こんにちは、@Yoshimiです。
今回は機械学習やそのkaggleコンペでもよく利用されているランダムフォレストについてまとめていきます。ランダムフォレストはざっくり申し上げますと「決定木を組み合わせた学習器」というイメージです。今ではライブラリを用いれば簡単にランダムフォレストを利用することができますが、もう少し裏側を知っておくとより理解が進みますよ。
アンサンブル学習
ランダムフォレストとは?を説明する前に、アンサンブル学習について少し知っておくことが良いです。ランダムフォレストとはアンサンブル学習の一つだからです。
アンサンブル学習とは、複数の学習器(モデル)を組み合わせてより良い精度を求める手法です。複数のモデルを訓練して各モデルの予測を最終的に多数決をして決めます。
ことわざでも三人寄れば文殊の知恵というのがあります。特別に頭の良い者でなくても三人集まって相談すれば何か良い知恵が浮かぶものということわざです。昔の人も上手に表現したものです。
例えば、現実世界でも一人で考えているより複数人で考えていく方がより良いアイデア・成果に繋がることがあると思います。それと一緒ですね。ただ、現実世界では大勢が集まってしまうと収集がつかないことも多いです。そこも似ているかもしれません。つまり、学習器も集めれば必ずしも良い成果につながるのか?という答えはノーです。この点はご注意ください。
アンサンブル学習は「バギング」「ブースティング」「スタッキング」と3つの手法に分けることができます。
バイアス / バリアンス
「バギング」「ブースティング」「スタッキング」の説明の前に、「バイアス(Bias)」と「バリアンス(Variance)」という大切なキーワードがあります。
バイアスとは、実際の値と予測の値との誤差の平均です。値が小さいほど真の値の誤差が小さいということです。バリアンスは予測値からどれだけ散らばっているのかを示す度合いのことで、こちらも散らばりが小さいほど真の値に近いということです。
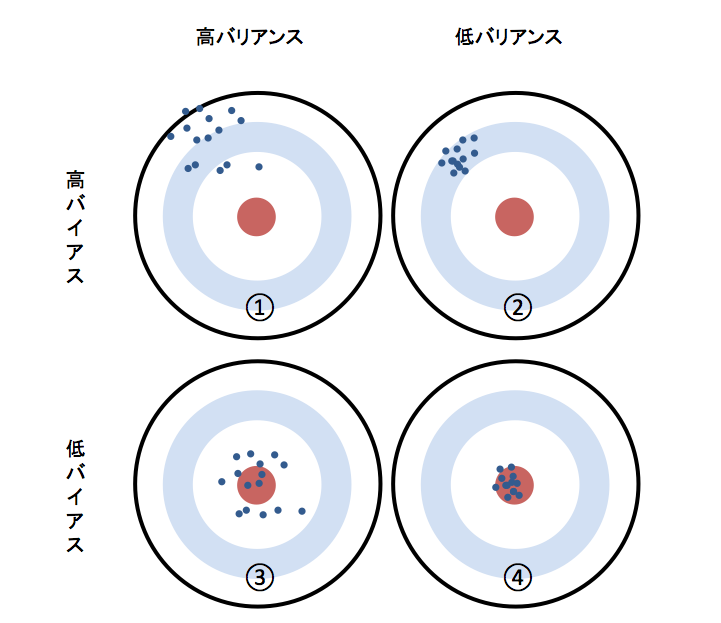 (引用:https://www.codexa.net/what-is-ensemble-learning/)
(引用:https://www.codexa.net/what-is-ensemble-learning/)
バギング
Bagging(バギング)は、bootstrap aggregatingの略です。
ブートストラップサンプリングという技術で得られた学習データを使って、複数の学習器を作成し、それらで多数決をとることで一つの学習器よりも性能の高いモデルを作ることが可能です。ブートストラップサンプリングとは、データセットからN個のデータをサンプリングする方法です。
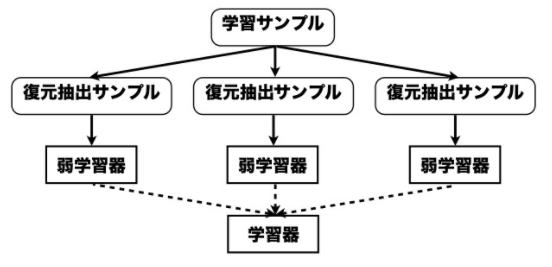 (引用:https://www.slideshare.net/holidayworking/ss-11948523)
(引用:https://www.slideshare.net/holidayworking/ss-11948523)
復元抽出サンプルとありますが、復元抽出とは、例えば、おみくじから一つくじを引きそれをまた箱に戻して再度1回引くという作業をNかい繰り返すというイメージです。
ブースティング
バギングでは弱学習器を独立して作りましたが、ブースティング(Boosting)は1つずつ順番に弱学習器を構成していきます。Kという弱学習器の次は弱点を補いK+1という弱学習器が誕生します。(逐次的に弱学習器を構築していくと表現します)
メリットは、弱点を補いながら学習器を構成できることでバギングより精度が高くなる傾向がありますが、デメリットとして時間がかかります。
有名どころ
- アダブースト
- マダブースト・ロジットブースト
- GBDT(Gradient Boosting Decision Tree)
- LightGBM
LightGBMは最強という説を聞いたことがありますが、解析するテーマにもよるのかなと思っています。あとで検証してみます。
スタッキング
スタッキング(Stacking)は言葉通り、モデルを積み上げていく方法です。学習器の第一段階の出力結果((例:ロジスティック回帰やランダムフォレスト))を次段の入力結果とする方法です。上手く利用することによりバイアスとバリアンスをバランスよく調整する事が可能です。
kaggleなどで上位入賞しているモデルをみるとこの手法も多く利用されております。
ランダムフォレストとは
ランダムフォレストとは、アンサンブル学習の中でもバギングを用いており、学習器として決定木を用いた手法です。決定木に関しては「決定木(Decision Tree)のアルゴリズムを少し覗いてみる」を読んでみてください。
決定木単体では過学習を起こしやすいというデメリット・欠点があります。ランダムフォレストでは、元のデータからランダムに何グループかにサンプリングをしているため、単一で評価するということをせず、複数の決定木で学習を行っていきます。それぞれ異なった方向に過学習をしている決定木があれば、平均をとり過学習分を減らしていく(すり合わせていくイメージ)という考えです。
ランダムフォレストの流れを簡単に説明するとこんな感じです。
- ランダムにデータを抽出する
- 決定木を成長させる
- 1,2のステップを繰り返し行う
- 多数決にて予測値を決定する
ランダムフォレストの特徴は以下の通りです。
- 予測精度が比較的高い
- 特徴量の重要度を評価できる
- 過学習(オーバーフィット)が起きにくい
- 並列処理可能
主要なパラメータ
デフォルトの設定のままでもある程度高い精度を出すことが可能ですが、ビジネスにと考えるとチューニングは必要です。ランダムフォレストの特に重要と思われる主要なハイパーパラメータを紹介します。
n_estimators
いくつの決定木を用意するかを設定します。大きければ大きいほど学習するので精度はよくなっていくかもしれません。しかし、その反面、全てを学習するまでに非常に時間がかかります。結果、コストもアップするかもしれません。最適なNを探す必要はあります。
max_features
特徴量の選択です。全ての特徴量がモデル構築に使われるわけではなく、特徴量もランダムに振り分けられます。max_featuresを大きくすれば、各決定木の結果は同じような結果が得られるでしょう。特徴量が20個しかない状態で、max_featuresと設定すれば、同じような結果です。逆に、小さすぎると決定木そのものが大きく変わってきますが、fitしない決定木も出てくるでしょう。
いや〜難しいです。
ランダムフォレストのハイパーパラメータ一覧はこちら(RandomForestClassifier)を参照してください。
実装してみる(簡易版)
scikit-learnのdatasetsにあるmake_moonsを使ってランダムフォレストを実装します。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=100, noise=0.25, random_state=3)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y,
random_state=42)
forest = RandomForestClassifier(n_estimators=5, random_state=2)
forest.fit(X_train, y_train)
パラメータはn_estimators=5, random_state=2とし、5つの決定木を用意します。
ccp_alpha=0.0,
class_weight=None,
criterion=’gini’,
max_depth=None,
max_features=’auto’,
max_leaf_nodes=None,
max_samples=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
n_estimators=5,
n_jobs=None,
oob_score=False,
random_state=2,
verbose=0,
warm_start=False)
mglearnはコードよ読みやすくするライブラリです。「Pythonではじめる機械学習」の著者が作成したものです。書籍の通りコードを実行するとModuleNotFoundError: No module named 'mglearn'とerrorが出ることが多いらしいです。QAサイトでも困っている方も多いようですね。
mglearnでerrorが出た方は下記プログラムを実行してください。
!pip install mglearn
それでもerrorが出る方は一度フォルダを確認してください。そうすると、mglearnというフォルダができておりそこに各プログラムが格納されていると思います。import mglearnで読み込めるようになっているはずです。
%matplotlib inline
import mglearn
fig, axes = plt.subplots(2, 3, figsize=(20, 10))
for i, (ax, tree) in enumerate(zip(axes.ravel(), forest.estimators_)):
ax.set_title("Tree {}".format(i))
mglearn.plots.plot_tree_partition(X_train, y_train, tree, ax=ax)
mglearn.plots.plot_2d_separator(forest, X_train, fill=True, ax=axes[-1, -1],
alpha=.4)
axes[-1, -1].set_title("Random Forest")
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
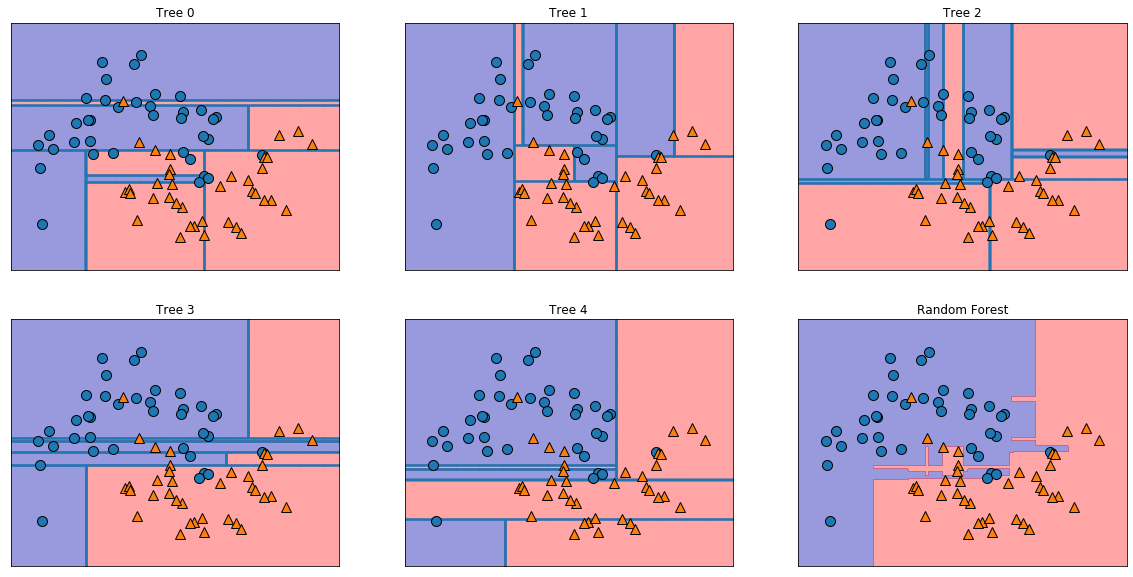 tree0〜tree4まで5つの決定木が
tree0〜tree4まで5つの決定木が
出力され、RandamuForestという5つの結果をもとに平均化した決定境界です。
もう一つの例で、cancerのデータセットで確認してみます。乳がんの診断データがまとめられたデータセットです。n_estimators=100として100個の決定木を用いたランダムフォレストを適用してみます。
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
print("cancer.keys():\n", cancer.keys())
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, random_state=0)
forest = RandomForestClassifier(n_estimators=100, random_state=0)
forest.fit(X_train, y_train)
print("Accuracy on training set: {:.3f}".format(forest.score(X_train, y_train)))
print("Accuracy on test set: {:.3f}".format(forest.score(X_test, y_test)))
dict_keys([‘data’, ‘target’, ‘target_names’, ‘DESCR’, ‘feature_names’, ‘filename’])
Accuracy on training set: 1.000
Accuracy on test set: 0.972
n_estimators=100以外、パラメータの調整を行っていないにも関わらず97.2%の精度が出ました。
決定木と同様に、ランダムフォレストでも特徴量の重要度を確認することが可能です。
def plot_feature_importances_cancer(model):
n_features = cancer.data.shape[1]
plt.barh(np.arange(n_features), model.feature_importances_, align='center')
plt.yticks(np.arange(n_features), cancer.feature_names)
plt.xlabel("Feature importance")
plt.ylabel("Feature")
plt.ylim(-1, n_features)
plot_feature_importances_cancer(forest)
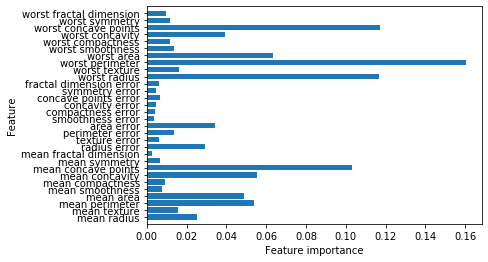 上の図を確認してもわかるように、決定の場合よりはるかに多くの特徴量に対して0以上の重要度を与えています。
上の図を確認してもわかるように、決定の場合よりはるかに多くの特徴量に対して0以上の重要度を与えています。
参考:Pythonで始める機械学習 2.3.6.1 ランダムフォレスト
最後に
今回はライブラリを用いてモデル作成して、検証してみました。高精度ということはわかりましたが、テキストデータなどの非常に高次元のデータに対しては高い精度を出すことができないようです。そのようなデータには線形モデルの方が適しているようです。なので、テーブルデータで検証する場合、他のアルゴリズムと比較要素として必ず利用したいアルゴリズムとしてストックしておいても良いと思います。
それにしても、ライブラリは非常に便利ですね。時間が空いた時はより理解力を深めるためにスクラッチで実装してみたいと思います。
参考:
http://segafreder.hatenablog.com/entry/2016/05/24/235822
https://qiita.com/renesisu727/items/09d9e88ab4e14ab034ed
https://www.codexa.net/what-is-ensemble-learning/
なりたい自分になれる
スキルアップならUdemy
私も利用し、高収入エンジニアになったのよ。未経験から機械学習、データサイエンティスト、アプリ開発エンジニアを目指せるコンテンツが多数あります。優秀な講師が多数!割引を利用すれば1,200円〜から動画購入可能です。!



