
こんにちは、@Yoshimiです。
機械学習、データ分析といえばPandasです。CSV以外、Excelやテーブルデータhtmlなども読み込める非常に優秀なライブラリなのです。そんなPandasの使い方基礎をご紹介します。
| read_csv | ファイルやURL、ファイル系オブジェクトから、区切り文字で区切られたデータなど |
| read_table | |
| read_excel | Excelデータからテーブル形式のデータを読み込む |
| read_html | 指定されたHTML文書に含まれるあらゆるtableデータを読み込む |
| read_pickle | Pythonのpickle形式のファイルを読み込む |
| read_sql | SQLクエリを発行した結果をpandasデータフレームとして読み込む |
他にも多数ありますが、私が実務で主に使う関数をピックアップしました。
データを読み込む
モジュールの読み込みを必ずします。あらゆる場面で利用しますので、import pandas as pdは呪文のように覚えてしまいましょう。
import pandas as pd
df = pd.read_csv('examples/ex1.csv')
df
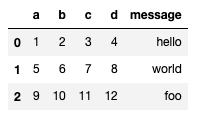
ead_tableを使って読み込む場合は、sep=','が必要になります。
pd.read_table('examples/ex1.csv', sep=',')
データフレームにヘッダーカラムを任意で追加する時は names= を記述します。ヘッダーカラムがない場合は、header=Noneとします。
pd.read_csv('examples/ex2.csv', names=['a', 'b', 'c', 'd', 'message'])
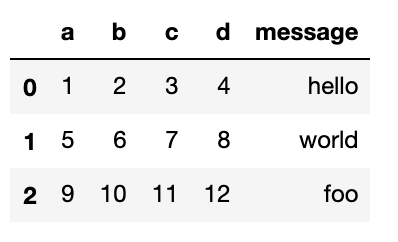
message列をデータフレームのインデックスにする場合は、index_col=’message’と記述します。
names = ['a', 'b', 'c', 'd', 'message']
pd.read_csv('examples/ex2.csv', names=names, index_col='message')

フィールドの区切りが”空白”であったり、”,”でない場合もあります。”空白”の場合、read_tableに正規表現を与えて区切りを文字を指定できます。”空白”の場合、区切りは\s+という正規表現で表すことが可能です。
[‘ A B C\n’,
‘aaa -0.264438 -1.026059 -0.619500\n’,
‘bbb 0.927272 0.302904 -0.032399\n’,
‘ccc -0.264273 -0.386314 -0.217601\n’,
‘ddd -0.871858 -0.348382 1.100491\n’]
‘aaa -0.264438 -1.026059 -0.619500\n’,
‘bbb 0.927272 0.302904 -0.032399\n’,
‘ccc -0.264273 -0.386314 -0.217601\n’,
‘ddd -0.871858 -0.348382 1.100491\n’]
なデータがあるとします。
result = pd.read_table('examples/ex3.txt', sep='\s+')
result
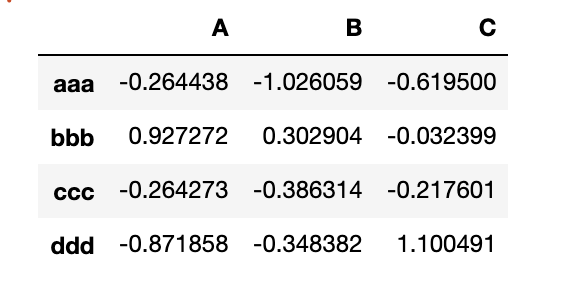
read_csvやread_tableでよく使われる引数を紹介します。
- path:ファイルシステム上の位置やURLなど、つまりPATH
- sep:各行をフィールドに分割するのに用いる文字列あるいは正規表現
- header:列名として使う行の番号。ヘッダーがない場合はheader=’None’
- index_col:行のインデックスとして使われる列の番号か名前
- names:戻り値として得られるオブジェクトの列名かリスト
- encoding:文字コード
- keep_date_col:複数の列を結合して日付として読み込む場合に、結合に用いられた列を残す
- date_parser:日付を読み込むのに用いる
データを出力する
data = pd.read_csv('examples/ex5.csv')
data
examplesフォルダにex5.csvファイルが出力されます。
なりたい自分になれる
スキルアップならUdemy
私も利用し、高収入エンジニアになったのよ。未経験から機械学習、データサイエンティスト、アプリ開発エンジニアを目指せるコンテンツが多数あります。優秀な講師が多数!割引を利用すれば1,200円〜から動画購入可能です。!





