
こんにちは、@Yoshimiです。
データフレームを作成する際、どのデータから読み込まれているのかを把握しておくと意外と便利だったりします。どんなデータが読み込まれているのか表示しておくプログラムを紹介します。
概要
- mac os
- python 3.8
- Jupyter Notebook 利用
data
├ data_01.csv
├ data_02.csv
├ data_20.csv
csv_data
├ 空のディレクトリ・・・あとで使います。
dataというフォルダに複数CSVが格納されています。この格納されてるデータを結合し、結合したデータの1つ1つにどのファイルから読み込まれたのかをまとめたデータフレームにします。ファイル名はfileというカラムを作成し、入力していきます。
最終形態はこうです。
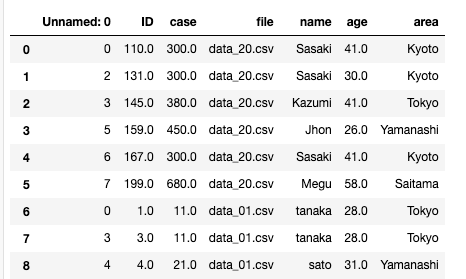
コード
基本モジュールを読み込みます。
import numpy as np import pandas as pd import glob import os
dataディレクトリにあるCSVをまとめます。
data_lists = glob.glob('data/*.csv')
data_lists
fileカラムに入力する値を確認します。ファイルまでのPATHは不要です。os.path.basename()を使います。
f_name = os.path.basename(data_lists[1]) f_name
データの中身を確認しておきます。
df_sample = pd.read_csv('data/data_01.csv')
df_sample
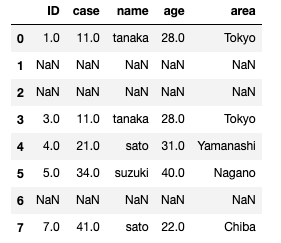 今回のデータは、
今回のデータは、
- 全てのカラムに欠損値がある行がある
- 重複caseが存在する
データで欠損値は処理を行う必要があります。全てのカラムで欠損値が見られるのであればその行は削除しても問題ないでしょう。ということで削除対象です。削除処理も合わせて行います。
流れはこうです。
- csvファイルを読み込む
- 欠損値の行を削除
- ファイル名を変数に代入
- fileカラムを作成し、任意(今回は2番目)にカラム追加
- 出力用の変数作成
- csv_dataフォルダにcsvを出力
の流れをfor文でdata_listsの数だけ回します。
for i in range(len(data_lists)):
df = pd.read_csv(data_lists[i])
df = df.dropna(how='all')
file_name = os.path.basename(data_lists[i])
df.insert(2, 'file', file_name)
csv_name = os.path.splitext(os.path.basename(file_name))[0]
df.to_csv('csv_data/'+ csv_name + 'Edit.csv')
出力されたCSVのファイル名でリストを作成します。
df_files = glob.glob('csv_data/*.csv')
df_files
‘csv_data/data_01Edit.csv’,
‘csv_data/data_02Edit.csv’]
リストを結合ます。
df = [pd.read_csv(df_files[i], parse_dates=[0]) for i in range(len(df_files))] df_all = pd.concat(df, ignore_index=True) df_all
結合されたデータを確認します。
この後の処理としては、使い所にもよります。
- 同じIDをまとめる
- カウントする
- 文字列を結合する
- 平均をとる
などなど、目的に合わせた使い方ができると思います。
ファイルの置き場所、読み込まれる場所、出力先などはもちろんお任せします。
最後に
「データ分析にファイル名いるの?」というツッコミがあると思いますが、私もそう思っていました。しかし、全件チェックしないといけないデリケート案件はAIの判定を理由に「確認しなかった」ということはあってはいけないことだと思います。
『ドクターX ~外科医・大門未知子~』でAIを取り入れ病名を判断し、それに従って処方をするという場面がありましたが、正直怖いなと思いました。一方、AIの限界というのも感じられた場面でもありました。
なりたい自分になれる
スキルアップならUdemy
私も利用し、高収入エンジニアになったのよ。未経験から機械学習、データサイエンティスト、アプリ開発エンジニアを目指せるコンテンツが多数あります。優秀な講師が多数!割引を利用すれば1,200円〜から動画購入可能です。!




