
こんにちは、@Yoshimiです。
データ分析の練習として、SIGNATEの練習問題に取り組んでみたので備忘録として残しておきます。ランキングは温かい目で見てください。
今回、チャレンジするのは「お弁当の需要予測」です。
目次
データ概要
お弁当の需要予測は「お弁当がどれだけ売れるのか?を予測する回帰問題」です
曜日やメニュー等の複数の変数から最適なお弁当の量を推測し、お弁当屋さんと、その利用者、そして環境に貢献するという課題です。
どのようなデータになっているかというと下記のようなデータ構成です。
| カラム | ヘッダ名称 | データ型 | 説明 |
|---|---|---|---|
| 0 | datetid | datetime | インデックスとして使用する日付(yyyy-m-d) |
| 1 | y | int | 販売数(目的変数) |
| 2 | week | char | 曜日(月~金) |
| 3 | soldout | boolean | 完売フラグ(0:完売せず、1:完売) |
| 4 | name | varchar | メインメニュー |
| 5 | kcal | int | おかずのカロリー(kcal)欠損有り |
| 6 | remarks | varchar | 特記事項 |
| 7 | event | varchar | 13時開始お弁当持ち込み可の社内イベント |
| 8 | payday | boolean | 給料日フラグ(1:給料日) |
| 9 | weather | varchar | 天気 |
| 10 | precipitation | float | 降水量。ない場合は “–” |
| 11 | temperature | float | 気温 |
データ・モジュールの読み込み
Google Colaboratoryでの解析になるので、CSVやTSVファイルの読み込みで違いがあるかもしれません。
import scipy as sp import numpy as np import pandas as pd import matplotlib import sklearn # 前処理用 from sklearn.preprocessing import StandardScaler #データを切り分ける from sklearn.model_selection import train_test_split from sklearn.model_selection import RandomizedSearchCV from sklearn.linear_model import LinearRegression,Ridge from sklearn.tree import DecisionTreeRegressor from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor #便利ツール from sklearn.pipeline import Pipeline #評価方法 from sklearn.metrics import r2_score from google.colab import files
from google.colab import filesがGoogle Colaboratoryファイルを読み込むコードです。もちろん他の方法もあるのですが、初心者向きということで非常に重宝しています。
ファイルを読み込むコードになります。
uploaded = files.upload()
アップロードボタンで表示されるので、そこからデータをアップロードしてください。
train、testにデータを格納します。
bento_sample.csvは提出データになるので、sampleという変数にデータを格納しておきます。
train = pd.read_csv('bento_train.csv')
test = pd.read_csv('bento_test.csv')
sample = pd.read_csv('bento_sample.csv', header=None)
trainデータの中身を簡単にチェックしてみます。
train.head()

今回は、yが目的変数になるので、y以外のカラムを利用しモデルを作成します。
ということで、yを除外したデータセットを作る必要があります。
trainX = train.drop('y', axis=1)
trainX.head()
指定した行・列を削除するdrop()関数を利用しyをdropし、新しいデータセットtraiXを作成します。axis=1は列を選択。ちなみに、axis=0は行が対象になります。
目的変数になるデータ「y」trainから取り出し、新たに変数「y」を作成し、yを代入します。
y = train['y']
testデータも確認してみます。
test.head()
 trainデータと違い「y」がありません。ということで、testデータはそのまま使います。copy()関数を使い、testXへ代入します。
trainデータと違い「y」がありません。ということで、testデータはそのまま使います。copy()関数を使い、testXへ代入します。
testX = test.copy()
やっとモデル作成のための準備データの基礎の訓練データと検証用データが完成しました。
- trainX
- testX
- y:求める変数でtrainから抽出した値
各種データのindex数、column数をチェックします。
print('trainX:', trainX.shape)
print('testX:', testX.shape)
print('y:', y.shape)
- trainX: (207, 11)
- testX: (40, 11)
- y: (207,)
trainX、testXでカラム数が合っています。
データクリーニング
データクリーニングとして以下の3つの処理が一般的であり、やらなくてはいけない基本的な部分です。
- 不要なデータの削除
- 欠損値の確認(保管)
- 質的データ(カテゴリーデータ)の確認、ダミー変数化
そのために、データの中身を確認し、どのような処理が良いのかを考えていきます。
まずはデータの中身をチェックします。
print('trainX.isnull().sum()')
print('testX.isnull().sum()')
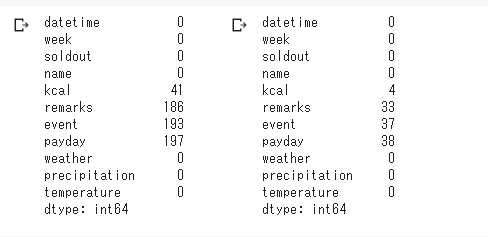 isnull().sum()は欠損値の合計を計算する関数です。上記計算から、いくつかのcolumnで欠損値があることがわかります。このままではデータ分析に支障がでるので、どうにかして穴埋めしていく必要があります。とうことを覚えておきましょう。
isnull().sum()は欠損値の合計を計算する関数です。上記計算から、いくつかのcolumnで欠損値があることがわかります。このままではデータ分析に支障がでるので、どうにかして穴埋めしていく必要があります。とうことを覚えておきましょう。
不要なデータの削除
「あれ、欠損値の値を調べたのに不要なデータの削除処理を最初にやるの?」と思ったかもしれません。
理由は、今の時点で、私のなかでどう処理したらわからないデータ(説明変数)があるので処理をしてしまいます。
- remarks:特記事項
- event:13時開始お弁当持ち込み可の社内イベント
- payday:給料日フラグ(1:給料日)
です。
remarks:特記事項は欠損値でも186、33と高い数値が確認できました。ユニークなテキストが格納されており、この部分を解析に入れ込むのはパターンなど確認する技術が高難易度な気がするので、削除を選びます。
event:13時開始お弁当持ち込み可の社内イベントはもしかしたら、こういううベントがあるのかないのか?などが、販売需要に関係あるかもしれませんが、今のところ処理から外します。
payday:給料日フラグ(1:給料日)は(1:給料日)とヒントがあるので、本当処理をすべき部分だと思います。ご結婚されている方は考えると思いますが、奥様からお弁当を準備されることも多々あります。せめて給料日は外で外食をしたいものですよね。という心理です。
さてさて、3つ説明変数と不要であろう勝手に決め、説明変数を削除します。
trainX = trainX.drop(['remarks', 'event', 'payday', 'name', 'precipitation', 'datetime' ], axis=1) testX = testX.drop(['remarks', 'event', 'payday', 'name', 'precipitation', 'datetime' ], axis=1)
欠損値の補完
kcalに欠損値がありました。女性であればkcalを控えめにしたいなどそういう要望もあるでしょう。ということはお弁当に関係のありそうな説明変数と考えることができ、削除できません。よって補完対象となります。
欠損値の補完には
- 平均値:mean
- 中央値:median
- 最頻値:mode
などで埋めることが多いです。
では
「どの値でを欠損値を埋めるのが最適なのか?」
という問題ですが、各データの関係を確認する必要があります。平均、偏差、分散、標準偏差などを確認するというイメージです。今回は割愛します。
さて、今回は、中央値で欠損値を埋めます。median()関数を使います。
trainX["kcal"] = trainX["kcal"].fillna(trainX["kcal"].median()) testX["kcal"] = testX["kcal"].fillna(testX["kcal"].median())
ダミー変数化(One-Hotエンコーディング)
ダミー変数化とは、カテゴリーデータを計測できるようデータ化する処理です。(と思っています。)または、One-Hotエンコーディングとも呼びます。
One-Hot、つまり1つだけ1でそれ以外は0のベクトル(行列)を指します。経済学や統計学では「ダミー変数」と呼ばれることもあります。ということでダミー変数化と呼びます。
weatherのデータは天気データが格納されておりますが、objectになっておりそのままでは処理ができません。
これを数値化するのです。「快晴」だったら「1」、「雨」だったら「2」という形に数値化をします。
pd.get_dummies()を使い、ダミー変数化を行います。
#文字列を数値に変換する
ohe_columns = ['week',
'weather']
# カテゴリカル変数を、one hot encoding(train)
trainX = pd.get_dummies(trainX, dummy_na=False, columns=ohe_columns)
# カテゴリカル変数を、one hot encoding(train)
testX = pd.get_dummies(testX, dummy_na=False, columns=ohe_columns)
今回は、「week」「weather」に焦点を合わせました。
月曜売れ筋、天気によって人気商品があるのか?などをチェックすることが可能になります。
testXtrainXの説明変数をチェックすると説明変数に差分があります。
- ‘weather_雪’
- ‘weather_雷電’
の処理を行います。
testXにはそもそもweather_雪、weather_雷電がないため、ダミー変数化を行った際、columnsとして生成されませんでした。なので、説明変数の数に差分があるわけです。
#trainデータの不要と思われる列の削除 trainX = trainX.drop(['weather_雪', 'weather_雷電'], axis=1)
モデルの構築
trainXをベースにtrain_test_splitし、モデルを検証してみます。
# ホールドアウト(Xとyに切っていく)
X_train,X_test,y_train,y_test = train_test_split(trainX,
y,
test_size=0.20,
random_state=1)
test_size=0.20はデータを8:2で分割します。random_state=1の「1」はどんな数字でも構いません。ただ、毎回ランダムで違ったデータで処理されるのを防ぐために「1」を固定数字を指定します。
Pipeline では、その名のごとく一連の処理をパイプラインで表現する便利ツールです。 具体的には、リストにscikit-learn のオブジェクトを適用する順番で格納していきます。
# pipeline setting
pipelines = {
'ols': Pipeline([('scl',StandardScaler()),
('est',LinearRegression())]),
'ridge':Pipeline([('scl',StandardScaler()),
('est',Ridge(random_state=0))]),
'tree': Pipeline([('scl',StandardScaler()),
('est',DecisionTreeRegressor(random_state=0))]),
'rf': Pipeline([('scl',StandardScaler()),
('est',RandomForestRegressor(random_state=0))]),
'gbr1': Pipeline([('scl',StandardScaler()),
('est',GradientBoostingRegressor(random_state=0))]),
'gbr2': Pipeline([('scl',StandardScaler()),
('est',GradientBoostingRegressor(n_estimators=200,
random_state=0))])
}
ツリー系のアルゴリズム(ランダムフォレストや勾配ブースティングなど)を除き、通常、機械学習モデルは入力ベクトルのスケールを統一させる必要があります(StandardScalerで対応)。ここではその処理をPipelineに組み込み対応しています。
scoresというdictを作成し、精度を表示させる箱を作ります。
評価指標はr2_score
# build and evaluate
scores = {}
for pipe_name, pipeline in pipelines.items():
pipeline.fit(X_train, y_train)
scores[(pipe_name,'train')] = r2_score(y_train, pipeline.predict(X_train))
scores[(pipe_name,'test')] = r2_score(y_test, pipeline.predict(X_test))
pd.Series(scores).unstack()
出た結果が・・・・
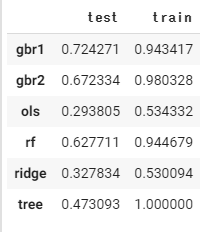 クソみたいな結果です・・・理由は天気のカテゴリーデータを強引にダミー変数化したからかなとも思っています。
クソみたいな結果です・・・理由は天気のカテゴリーデータを強引にダミー変数化したからかなとも思っています。
モデルを作成する
クソ結果になりましたが、ともあれモデルを作成し、signateに投稿する一連をしたいと思います!(あきらめ状態)
評価のチェック方法ですが、trainとtestの精度がいい具合のモデルをつかうと良いといわれたことがあります。ただ上の結果をみるとどれもよくないので、名前のかっこいいGradientBoostingRegressorでモデルを作成します。modelにfit()関数をあて、説明変数、目的変数で設定します。
model = GradientBoostingRegressor() model.fit(trainX, y)

予測値をだす
model.fitは訓練データでした。予測するには検証データを使います。testXです。
pred = model.predict(testX) pred
 予測数値がでました。今回は回帰分析なのでかなり詳細な数値が出ています。
予測数値がでました。今回は回帰分析なのでかなり詳細な数値が出ています。
この予測を提出データsampleに代入します。
sample[1] = pred
最後に、提出データcsvに反映させ、出力して完了です。
sample.to_csv('GradientBoostingRegressor.csv', index=None, header=None)
最後に
暫定評価:45.33253でした。順位はかなり下のほうです。
過去、別の方法でモデル構築したほうがよかった・・・
今回紹介したプログラム
[SIGNATE練習問題]お弁当の需要予測はUdemyでも動画で配信されています。1,000円台でPythonでのデータ分析が学べて、コンペ参加もできるのでかなりおすすめです。お弁当需要予測は参加6500人以上の参加、データ投稿18300件以上!他にも初心者向けコンペがあるので、動画で学んで参加してスキルアップを目指してください。
なりたい自分になれる
スキルアップならUdemy
私も利用し、高収入エンジニアになったのよ。未経験から機械学習、データサイエンティスト、アプリ開発エンジニアを目指せるコンテンツが多数あります。優秀な講師が多数!割引を利用すれば1,200円〜から動画購入可能です。!






