
こんにちは、@Yoshimiです。
データ分析の練習としてSIGNATEの【練習問題】アワビの年齢予測に取り組んでみたので備忘録として残しておきます。ランキングは温かい目で見てください。
目次
データ概要
アワビの計測データからアワビの年齢を予測するモデルを作成していただきます
アワビの年齢は、殻を切断し、染色し、顕微鏡で輪の数を数えることによって知ることができますが、これはとても時間のかかる作業です。もっと簡単に取得できる他の測定値を用いて年齢を予測することで、この退屈な作業を簡略化しましょう!
| カラム | ヘッダ名称 | データ型 | 説明 |
|---|---|---|---|
| 0 | id | int | インデックスとして使用 |
| 1 | Sex | char | 性別 |
| 2 | Length | float | 長さ |
| 3 | Diameter | float | 直径 |
| 4 | Height | float | 高さ |
| 5 | Whole weight | float | 全体の重量 |
| 6 | Shucked weight | float | 身の重量 |
| 7 | Viscera weight | float | 内臓の重量 |
| 8 | Shell weight | float | 殻の重量 |
| 9 | Rings | int | 年齢(1~29) |
みなさんはアワビを頻繁に食べるのでしょうか?私もそんなに食べたことはありません。学生時代和食店でアルバイトしているとき、アワビがメニューに入っていて試食する程度だったと思います。社会人になってからは一度もありません!誰かご馳走して欲しいです・・・。
モジュール・データの読み込み
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
import warnings
warnings.filterwarnings("ignore")
# 可視化ライブラリ
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
sns.set()
%matplotlib inline
今回はgoogle driveにデータを格納し、google colabで呼び出してデータを利用していきます。
from google.colab import drive
drive.mount('/content/drive')
データを確認していきましょう
train = pd.read_csv('/content/drive/My Drive/Colab Notebooks/data/awabi/awabi_train.tsv', delimiter='\t')
test = pd.read_csv('/content/drive/My Drive/Colab Notebooks/data/awabi/awabi_test.tsv', delimiter='\t')
sample = pd.read_csv('/content/drive/My Drive/Colab Notebooks/data/awabi/awabi_sample_submit.csv', header=None)
print('train{} / test{} / sample{}'.format(train.shape, test.shape, sample.shape))
OUT:train(2088, 10) / test(2089, 9) / sample(2089, 2)
目的変数との関係性を確認する
目的変数「Rings」と各特徴量の関係をチェックしていきます。
sns.pairplot(train, size=2) plt.tight_layout() plt.show()
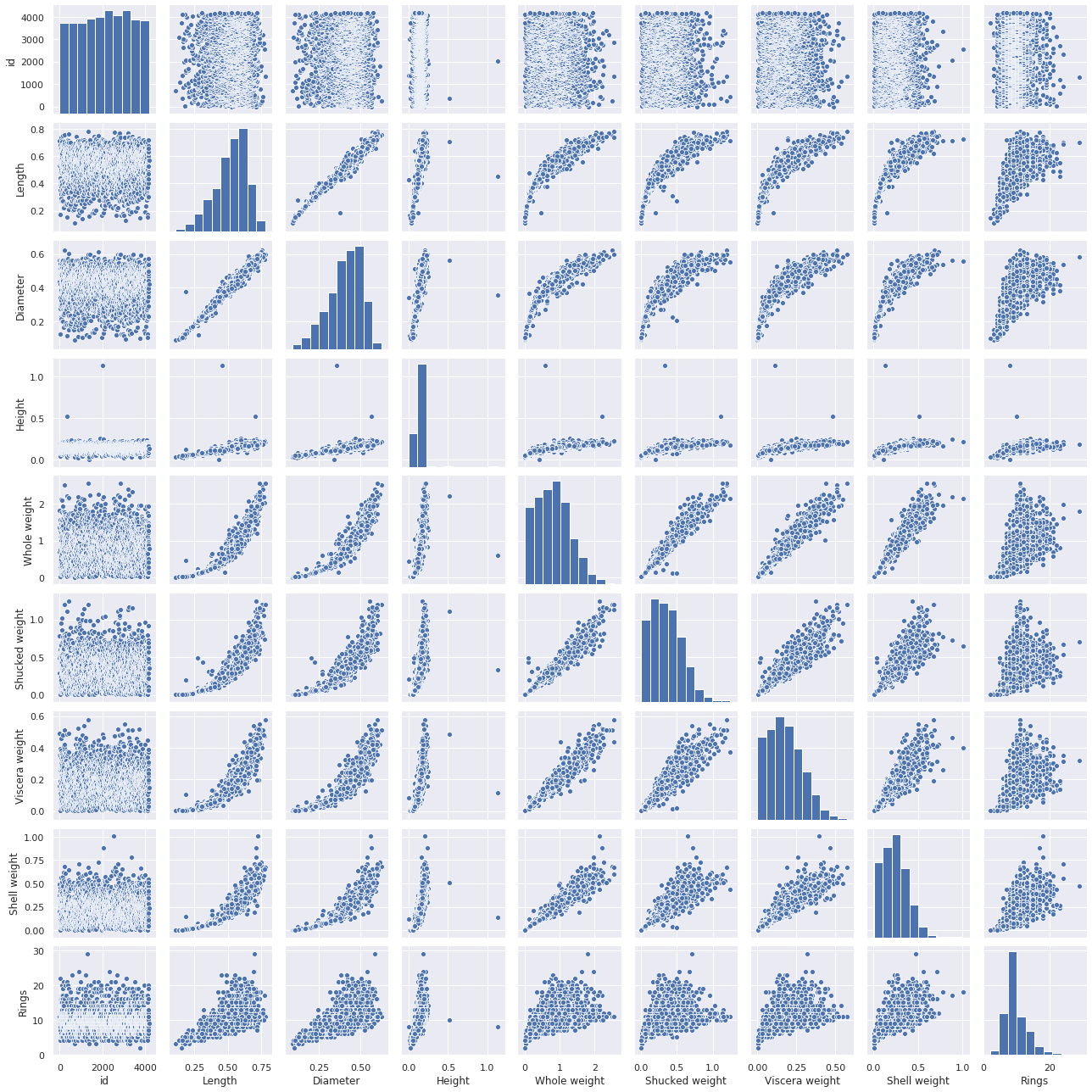 可視化できました。関係性が強そうなのは・・・LengthとDiameterあたりでしょうか?他にもShell weightもありますが、要検討です。Heightは外れ値の存在によって相関関係を確認しにくいですね。数値で相関の強さをチェックします。
可視化できました。関係性が強そうなのは・・・LengthとDiameterあたりでしょうか?他にもShell weightもありますが、要検討です。Heightは外れ値の存在によって相関関係を確認しにくいですね。数値で相関の強さをチェックします。
#相関係数を計算
train_corr = train.corr()
#ヒートマップを表示
plt.figure(figsize=(10, 10))
hm = sns.heatmap(train_corr,
cbar=True,
annot=True,
square=True,
annot_kws={'size':15},
fmt='.2f')
plt.tight_layout()
plt.show()
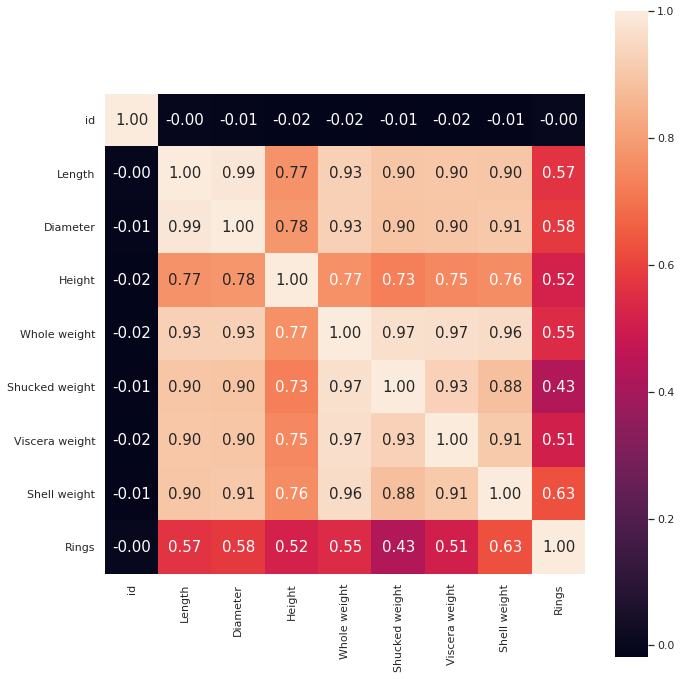 RingsはShell weightとの相関が最も強いことが分かります。
RingsはShell weightとの相関が最も強いことが分かります。
データクリーニング / 前処理
データを確認するとカテゴリーデータが存在し、そのままではモデルに利用することができませんですので、テーブルデータのクリーニング・前処理を行います。代表的な前処理は以下の通りです。(上級者はもっと多くのことをすると思います。)
- 欠損値の確認・穴埋め
- カテゴリーデータの処理(ダミー変数化)
- 外れ値の処理
カテゴリーデータの処理(ダミー変数化)
Sexをダミー変数化します。
#文字列を数値に変換する ohe_columns = ['Sex'] # カテゴリカル変数を、one hot encoding(train) train = pd.get_dummies(train, dummy_na=False, columns=ohe_columns)
外れ値の処理
散布図行列でHeightに外れ値があることがわかりました。削除していきます。
# 最も大きな値を抽出する train[train['Height'] > 1]

train = train[train['Height'] < 1] train.shape
ダミー変数化、外れ値の処理を行った結果の相関係数を見てみます。
#相関係数を計算
train_corr = train.corr()
#ヒートマップを表示
plt.figure(figsize=(10, 10))
hm = sns.heatmap(train_corr,
cbar=True,
annot=True,
square=True,
annot_kws={'size':15},
fmt='.2f')
plt.tight_layout()
plt.show()
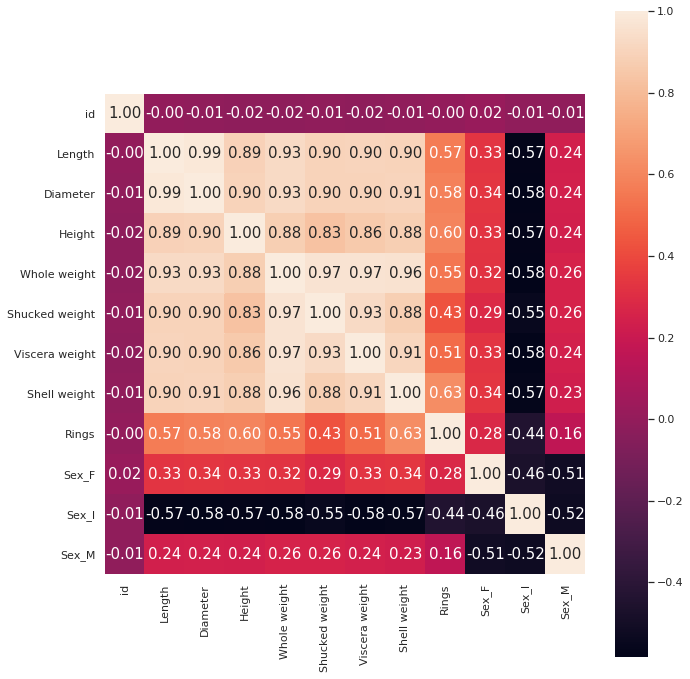 Heightの相関係数は上がりました。ダミー変数化を行った結果、相関が低い特徴量が見つかりましたので、Sex_FとSex_Mは削除対象とします。次にモデルの準備に入ります。
Heightの相関係数は上がりました。ダミー変数化を行った結果、相関が低い特徴量が見つかりましたので、Sex_FとSex_Mは削除対象とします。次にモデルの準備に入ります。
モデル構築の準備
モデル構築の準備をします。
今回求める目的変数はRingsなので、yへRingsを代入します。trainから削除する特徴量を削除し、train_Xへ代入。yとtrain_Xを作成し、検証モデルを作成するために、train_test_splitを利用します。
# 目的変数をyに代入する
y = train['Rings']
# trainの不要データを削除し、train_Xに代入
train_X = train.drop(['id','Rings','Sex_I','Sex_M'], axis=1)
#トレーニングデータとテストデータに分割
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(train_X, y, test_size=0.2, random_state=0)
print('{},{},{},{}'.format(X_train.shape,X_test.shape,y_train.shape,y_test.shape))
OUT:(1669, 8),(418, 8),(1669,),(418,)
モデルの構築
特徴量の単位が一定でないため標準化します。
from sklearn.preprocessing import StandardScaler #データの標準化 sc = StandardScaler() sc.fit(X_train) X_train_std = sc.transform(X_train) X_test_std = sc.transform(X_test)
さて、ここからいくつかのモデル構築を行っていきます。
多変量線形回帰:LinearRegression
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train_std, y_train)
#R^2を表示
print("R^2:",lr.score(X_test_std, y_test))
OUT:R^2: 0.4865054006594162
パイプラインの導入
パイプライン(pipeline)を導入し、標準化から学習までをまとめて処理してみます。
# 上記内容と同じ結果
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import make_pipeline
#パイプラインで線形回帰モデルを構築
pipe_linear = make_pipeline(StandardScaler(),
LinearRegression())
#グリッドサーチで線形回帰を実施
gs = GridSearchCV(estimator=pipe_linear,
param_grid={},
scoring='r2',
n_jobs=-1)
gs = gs.fit(X_train, y_train)
#R^2を表示
print('R^2:',gs.score(X_test,y_test))
OUT:R^2: 0.4865054006594163
同じ結果がでました。for文でまわしたりすれば複数モデルを一括で処理もできると思います。日々精進。
Lasso回帰
Lasso回帰は最小二乗コスト関数に対して、重みの合計を足したもの(L1正則化項と呼びます)です。
#パイプラインをLasso回帰(L1)で構築
from sklearn.linear_model import Lasso
pipe_lasso = make_pipeline(StandardScaler(),
Lasso())
#パラメータを確認
pipe_lasso.get_params()
パラメータが表示されます。詳しくは公式サイトでチェックすることをお勧めします。
{'lasso': Lasso(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=1000,
normalize=False, positive=False, precompute=False, random_state=None,
selection='cyclic', tol=0.0001, warm_start=False),
'lasso__alpha': 1.0,
'lasso__copy_X': True,
'lasso__fit_intercept': True,
'lasso__max_iter': 1000,
'lasso__normalize': False,
'lasso__positive': False,
'lasso__precompute': False,
'lasso__random_state': None,
'lasso__selection': 'cyclic',
'lasso__tol': 0.0001,
'lasso__warm_start': False,
'memory': None,
'standardscaler': StandardScaler(copy=True, with_mean=True, with_std=True),
'standardscaler__copy': True,
'standardscaler__with_mean': True,
'standardscaler__with_std': True,
'steps': [('standardscaler',
StandardScaler(copy=True, with_mean=True, with_std=True)),
('lasso', Lasso(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=1000,
normalize=False, positive=False, precompute=False, random_state=None,
selection='cyclic', tol=0.0001, warm_start=False))],
'verbose': False}
正則化の強さである’alpha’を最適化対象のパラメータとしてグリッドサーチを実施します。
#パラメータの設定
param_grid = {'lasso__alpha':[0.001,0.01,0.1,1,10,100,1000]}
#グリッドサーチを実施
gs_lasso = GridSearchCV(estimator=pipe_lasso,
param_grid=param_grid,
scoring='r2',
n_jobs=-1)
gs_lasso = gs_lasso.fit(X_train, y_train)
#R^2、ベストパラメータを表示
print('R^2:',gs_lasso.score(X_test,y_test))
print('ベストパラメータ:',gs_lasso.best_params_)
OUT:R^2: 0.48711119099625944
ベストパラメータ: {‘lasso__alpha’: 0.001}
Ridge回帰
#パイプラインをRidge回帰(L2)で構築
from sklearn.linear_model import Ridge
pipe_ridge = make_pipeline(StandardScaler(),
Ridge())
#パラメータの設定
param_grid = {'ridge__alpha':[0.001,0.01,0.1,1,10,100,1000]}
#グリッドサーチを実施
gs = GridSearchCV(estimator=pipe_ridge,
param_grid=param_grid,
scoring='r2',
n_jobs=-1)
gs = gs.fit(X_train, y_train)
#R^2、ベストパラメータを表示
print('R^2:',gs.score(X_test,y_test))
print('ベストパラメータ',gs.best_params_)
OUT:R^2: 0.4866776898313726
ベストパラメータ {‘ridge__alpha’: 0.1}
ElasticNet回帰
LassoとRidgeをミックスしたElasticNet回帰を実施します。いいとこどりのモデルです。
#パイプラインをElasticNet回帰で構築
from sklearn.linear_model import ElasticNet
pipe_elasticnet = make_pipeline(StandardScaler(),
ElasticNet())
#パラメータの設定
param_grid = {'elasticnet__alpha':[0.001,0.01,0.1,1,10,100,1000],
'elasticnet__l1_ratio':[0.1,0.3,0.5,0.7,0.9]}
#グリッドサーチを実施
gs = GridSearchCV(estimator=pipe_elasticnet,
param_grid=param_grid,
scoring='r2',
n_jobs=-1)
gs = gs.fit(X_train, y_train)
#R^2、ベストパラメータを表示
print('R^2:',gs.score(X_test, y_test))
print('ベストパラメータ:',gs.best_params_)
OUT:
R^2: 0.48731289998133465
ベストパラメータ: {‘elasticnet__alpha’: 0.001, ‘elasticnet__l1_ratio’: 0.9}
さて一通りの「LinearRegression」「Lasso回帰」「Ridge回帰」「ElasticNet回帰」をチェックしたところ、わずかながらもElasticNet回帰が一番良いスコアになりました。従いまして、ElasticNet回帰でtestデータで予測を行っていきます。
Testデータのクリーニング・成形
trainデータで行ったデータクリーニングをTestデータでも行っていきます。
# ダミー変数化 test = pd.get_dummies(test, dummy_na=False, columns=ohe_columns) # Testの不要データを削除し、test_Xに代入 test_X = test.drop(['id','Sex_I','Sex_M'], axis=1)
予測する
# 予測 pred_cv = gs_el.predict(test_X) pred_cv

投稿用ファイルを作成し終了です。
sample[1] = pred_cv
sample.to_csv('awabi_gs_el.csv', index=None, header=None)
最後に
これからの課題はPipelineの作りこみ、複数モデルの一括評価、グリッドサーチ(GridSearchCV)の熟練度です。この辺りは専門的に調べてどんどん使えるようにしていきます。
アワビ食べたいな~。
なりたい自分になれる
スキルアップならUdemy
私も利用し、高収入エンジニアになったのよ。未経験から機械学習、データサイエンティスト、アプリ開発エンジニアを目指せるコンテンツが多数あります。優秀な講師が多数!割引を利用すれば1,200円〜から動画購入可能です。!






