
こんにちは、@Yoshimiです。
姪っ子と遊ぶのにポケモンは最強。世界共通語だとおもっています。ポケモンカードメルカリで見るとめっちゃ高いですよね。びっくりしちゃいました。
ポケモンのデータ解析はkaggleにもデータセットがあり、多くの方がチャレンジしており、出尽くした感があります。なので、私は、ポケモンゲームソードシールド(通称:剣盾)でどんなチーム構成をしたらよいのか?をゴールにおき、分析を行ってみたいと思います。
目次
ポケモンデータの大枠をとらえる
Google Colaboratoryをつかっていきます。
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt import matplotlib.patches as patches %matplotlib inline from google.colab import files
外部ファイルをインポートしていきます。
uploaded = files.upload()
外部ファイルを読み込んでください。
df = pd.read_csv('pokemon-swordshield.csv')
print(df.shape)
df.head()
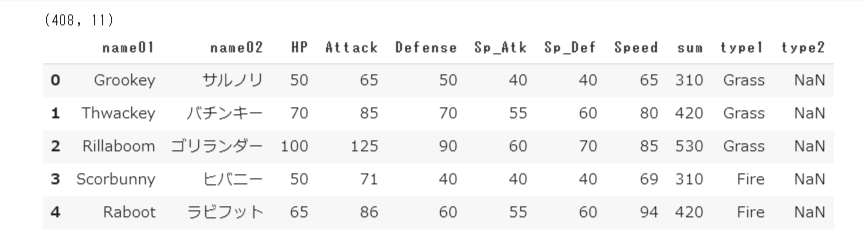 408のポケモンがおり、11の特徴量(カラム)があることがわかります。name01とname02のように2つnameがあるのは、Google Colaboratoryで分析していると豆腐(文字バケ)することがあり、解消させるのに時間を取られてしまうので、英語表記を追加しました。日本語はわかりやすいように残しておきます。
408のポケモンがおり、11の特徴量(カラム)があることがわかります。name01とname02のように2つnameがあるのは、Google Colaboratoryで分析していると豆腐(文字バケ)することがあり、解消させるのに時間を取られてしまうので、英語表記を追加しました。日本語はわかりやすいように残しておきます。
さて特徴量は以下の通りです。
- Name: Name of the Pokemon
- HP: Hit Points
- Attack: Attack Strength
- Defense: Defensive Strength
- Sp_Atk: Special Attack Strength
- Sp_Def: Special Defensive Strength
- Speed: Speed
- sun: Sum of Attack, Sp. Atk, Defense, Sp. Def, Speed and HP
- Type 1: Type of pokemon
- Type 2: Other Type of Pokemon
関係性を見ていくとどのポケモンがどういうパラメータになっているのか?属性によっても特徴があるなど確認できると思います。
分析の方向性・考えられること
ゴールはポケモン剣盾でバトルで勝つチーム編成を見つけるということです。
種族値(sum)、属性、弱点、有効打撃が気になっている部分です。種族値が高かったとしても、弱点を突かれる相手だった場合、弱点効果(こうかばつぐん!)で一撃で葬り去られる可能性も十分あり得ます。攻撃効果には、こうかばつぐん、いまいち、ノーマル、効果なし(ノーダメージ)という4段階があり、対戦するポケモンtypeにより大きく変わります。
すでに他のブログでもSpeed最強説などあり確かにそうなのかもしれませんが、私なりにどんなチーム編成がいいのかもしっかり考えていきたいと思います。
長丁場ですがお付き合いください。
ポケモン総数の全体を確認する
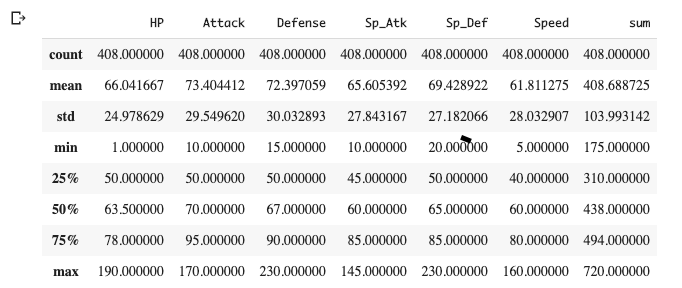
各特徴量の平均、中央値などを確認してみます。
df.describe()
わかりにくいので箱ヒゲ図で確認してみます。
df.plot.box()
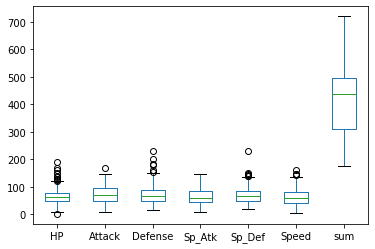 Sp_Def(特殊防御)に外れ値(この場合、優秀な値)があることがわかります。
Sp_Def(特殊防御)に外れ値(この場合、優秀な値)があることがわかります。
分析している方やポケモン愛好家の中では種族値が注目されています。種族値とは、HP、Attack、Defenseなどの数値を全て足した値で、ポケモンの基本的な力を表す値です。つまり総合的な強さを表しています。
sns.distplot(df["sum"]) plt.show()
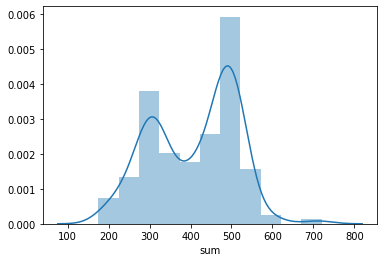 300族と500族あたりに山があることがわかります。たねポケモンのサルノリ310で2進化のゴリランダーが510、ユキカブリ334で進化のユキノオーが494と考えると進化ポケモンが500の種族値付近に集まっているいることなのでしょう。
300族と500族あたりに山があることがわかります。たねポケモンのサルノリ310で2進化のゴリランダーが510、ユキカブリ334で進化のユキノオーが494と考えると進化ポケモンが500の種族値付近に集まっているいることなのでしょう。
この種族値500付近にはどのようなtypeのポケモンが存在するのか確認します。ポケモンは2つのtypeを持つ場合があるので、type01とtype02を合算します。また1ポケモンで同じtypeはないです。例としてはサルノリがtype01草/type02草ということはないということです。
# メインtype poke_type01 = df['type1'].value_counts() poke_type01 = pd.DataFrame(poke_type01).T # サブtype poke_type02 = df['type2'].value_counts() poke_type02 = pd.DataFrame(poke_type02).T poke_type_join = pd.concat([poke_type01, poke_type02]) poke_type_join

イメージがしにくいので可視化してみます。
vals1 = [df['type1'].value_counts()[key] for key in df['type1'].value_counts().index] vals2 = [df['type2'].value_counts()[key] for key in df['type1'].value_counts().index] inds = np.arange(len(df['type1'].value_counts().index)) width = .45 color1 = np.random.rand(3) color2 = np.random.rand(3) handles = [patches.Patch(color=color1, label='type1'), patches.Patch(color=color2, label='type2')] plt.bar(inds, vals1, width, color=color1) plt.bar(inds+width, vals2, width, color=color2) plt.gca().set_xticklabels(df['type1'].value_counts().index) plt.gca().set_xticks(inds+width) plt.grid() plt.xticks(rotation=90) plt.legend(handles=handles)
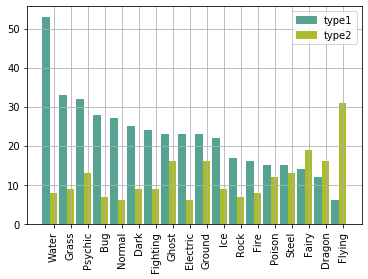 type1ではWatwerポケモンが多く、type2ではFlyingポケモンが多いようです。
type1ではWatwerポケモンが多く、type2ではFlyingポケモンが多いようです。
積み上げグラフ
総数としてどのtypeのポケモンが多いのか確認してみます。type1とtype2を合算して可視化してみます。
# データフレームの集計sum()を取る poke_type_total = poke_type_join.sum() poke_type_total fig, ax = plt.subplots(figsize=(12,6)) data_points = np.arange(len(poke_type_join.columns)) # 一番下の層のbarplot ax.bar(data_points, poke_type_join.iloc[0]) # 二番目の層のbarplot。bottomに1番目の層の値を指定している。 ax.bar(data_points, poke_type_join.iloc[1], bottom=poke_type_join.iloc[0]) ax.set_xticks(data_points) ax.set_xticklabels(poke_type_join.columns);
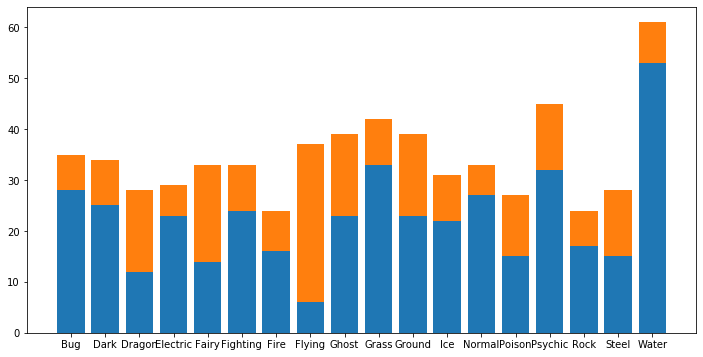
Water(水)が一番多く、Rock(岩)が一番少ないようです。割合はどのくらいなのでしょうか。
percent = poke_type_join.sum()/ poke_counts missing_data = pd.concat([poke_type_total, percent], axis=1, keys=['Total', 'Percent']).sort_values(by='Total', ascending=False) missing_data.head(18)
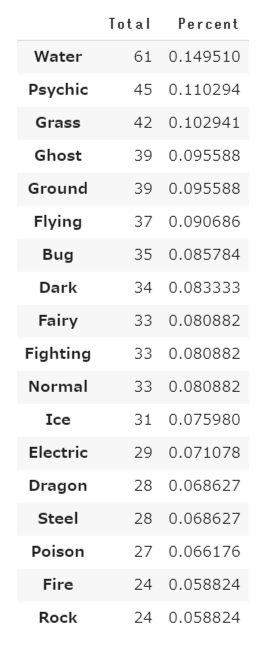 登録の多いポケモンはWater 14%、Psychic 11%、Grass 10%、Ghost 9.5%、Ground 9.5%となっております。
登録の多いポケモンはWater 14%、Psychic 11%、Grass 10%、Ghost 9.5%、Ground 9.5%となっております。
ここで、考えるべきポイントは
Water typeのポケモンが多く存在するので、バトルにもWater typeが多く選ばれているのか?
です。
高い種族値のポケモンを抽出
私的には、上のヒストグラムからみると種族値500以上は欲しいところですが、弱点・特性などを考慮するともう少し幅を幅を広げてもいいのかなと思っています。なので種族値480以上まで落とし確認ます。
poke_tribe = df[(df['sum'] > 480)] poke_tribe_list =len(poke_tribe) print(poke_tribe_list) print(poke_tribe.shape)
OUT:138
OUT:(138, 11)
種族値480以上のポケモンは138種類確認できました。138種類もいればこの中での組み合わせでチームが組まれると思います。ということでこの種族値480以上で且つtype別にどのくらいのポケモンがいるのかチェックしてみます。
# メインtype poke_type480_01 = poke_tribe['type1'].value_counts() poke_type480_01 = pd.DataFrame(poke_type480_01).T poke_type480_01 # サブtype poke_type480_02 = poke_tribe['type2'].value_counts() poke_type480_02 = pd.DataFrame(poke_type480_02).T poke_type480_02 poke_type_480_join = poke_type480_01.append(poke_type480_02) poke_type_480_join

percent = poke_type_480_join.sum()/ poke_tribe_list missing_data = pd.concat([poke_type_480_join.sum(), percent], axis=1, keys=['Total', 'Percent']).sort_values(by='Total', ascending=False) missing_data.head(18)
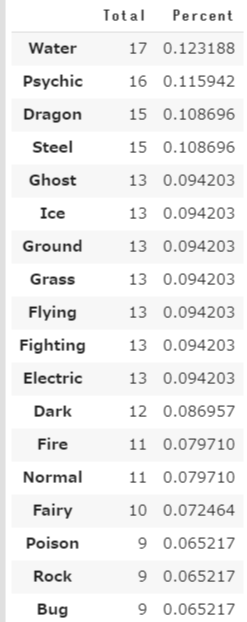
Water typeが17ポケモンおり、12.3%となっております。Psychic typeが16匹11.5%です。可視化します。
fig, ax = plt.subplots(figsize=(12,6)) data_points = np.arange(len(poke_type_480_join.columns)) # 一番下の層のbarplot ax.bar(data_points, poke_type_480_join.iloc[0]) # 二番目の層のbarplot。bottomに1番目の層の値を指定している。 ax.bar(data_points, poke_type_480_join.iloc[1], bottom=poke_type_480_join.iloc[0]) ax.set_xticks(data_points) ax.set_xticklabels(poke_type_480_join.columns);
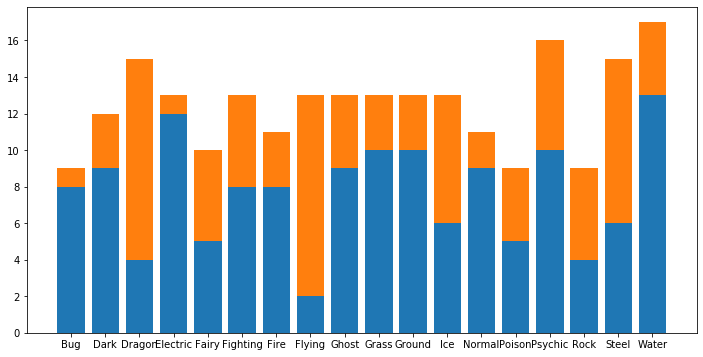 種族値480を超えるポケモンの種類はDragon、Psychic、Water、Steelが多いことがわかります。
種族値480を超えるポケモンの種類はDragon、Psychic、Water、Steelが多いことがわかります。
Dragon、Psychic、Water、Steelのポケモンがチーム編成されることが多いのでしょうか?
考察
ポケモン剣盾のバトル仕様も考慮し、どんなポケモンを編成したら勝率が良くなるのかを考えていきます。
ポケモンバトルでは
他のポケモンデータを解析しているブログでもSpeed最強と考察があるのでそれを参考にさせていただき、
- 弱点をつけることを重視する
- 選考1ターン目で倒せなくても、耐えることで2ターン目で倒す
と考えてみます。
人気そうなポケモンを抽出してみます。
poke_tribe_top = poke_tribe[poke_tribe['type1'].isin(['Dragon', 'Psychic', 'Water', 'Steel']) | poke_tribe['type2'].isin(['Dragon', 'Psychic', 'Water', 'Steel'])].sort_values(by='sum', ascending=False) poke_tribe_top.shape
(60, 11)
種族値が480以上あり、’Dragon’, ‘Psychic’, ‘Water’, ‘Steel’は60匹いることがわかりました。
基礎解析として、このポケモンたちの特徴量の散布図を確認していきます。
散布図
from pandas import plotting # 新しいバージョンではこちらを plotting.scatter_matrix(poke_tribe.iloc[:, 2:9], figsize=(8, 8)) plt.show()
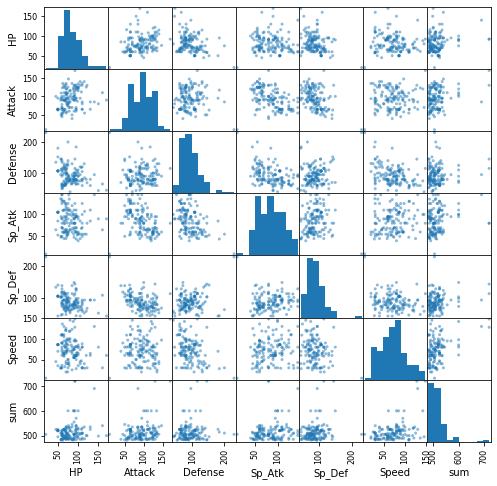
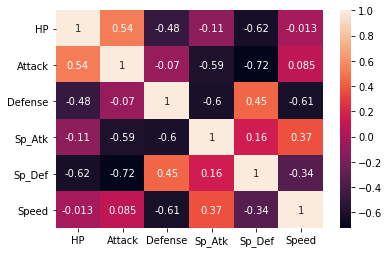
相関行列
poke_tribe_corr = poke_tribe.corr() poke_tribe_corr corr_math = (poke_tribe_corr.loc[:,['HP','Attack','Defense','Sp_Atk','Sp_Def','Speed']]).corr() sns.heatmap(corr_math,annot = True)
バイオリンプロット
バイオリンプロットは各変数の分布を眺めるいわゆるひとつの便利な方法です。
# 属性ごとに確認する
for index, type1 in enumerate(type1s):
poke_tribe2 = poke_tribe[poke_tribe['type1'] == type1]
fig = plt.figure(figsize=(8, 4))
ax = fig.add_subplot(1, 1, 1)
plt.title(type1)
ax.set_ylim([0, 280])
ax.violinplot(poke_tribe2.iloc[:, 2:8].values.T.tolist())
ax.set_xticks([1, 2, 3, 4, 5, 6]) #データ範囲のどこに目盛りが入るかを指定する
ax.set_xticklabels(poke_tribe2.columns[2:8], rotation=90)
plt.grid()
plt.show()
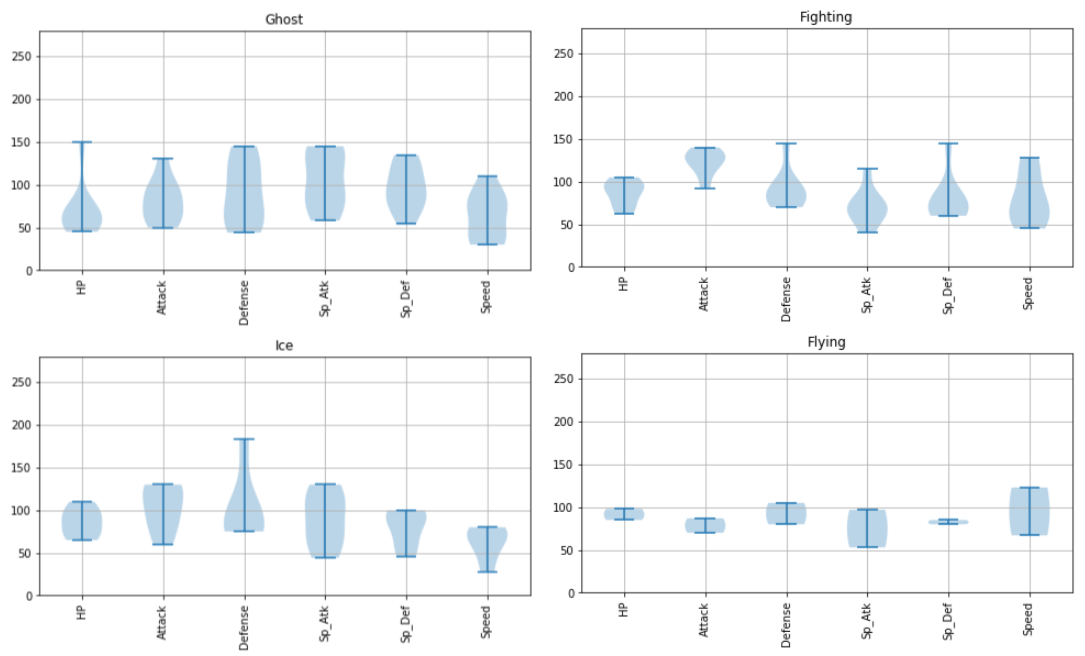
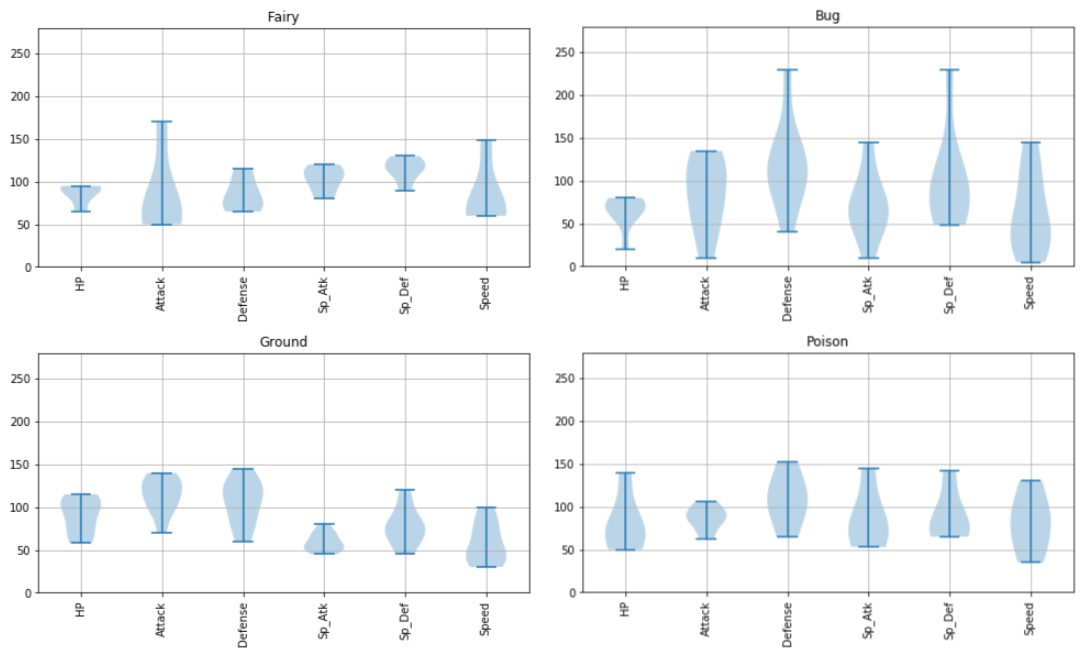
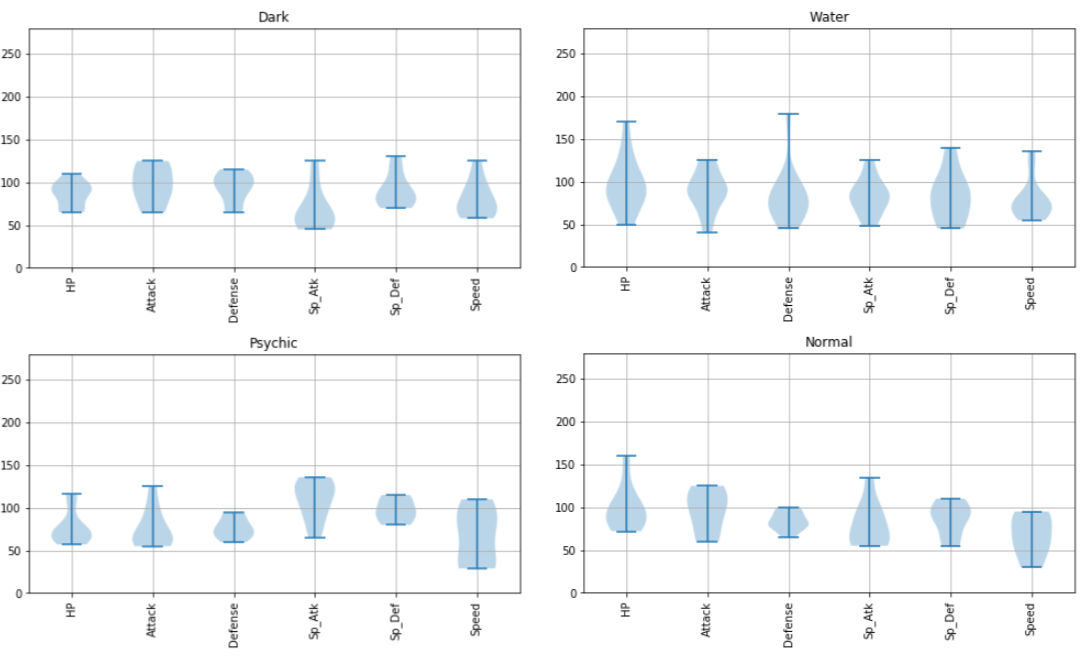
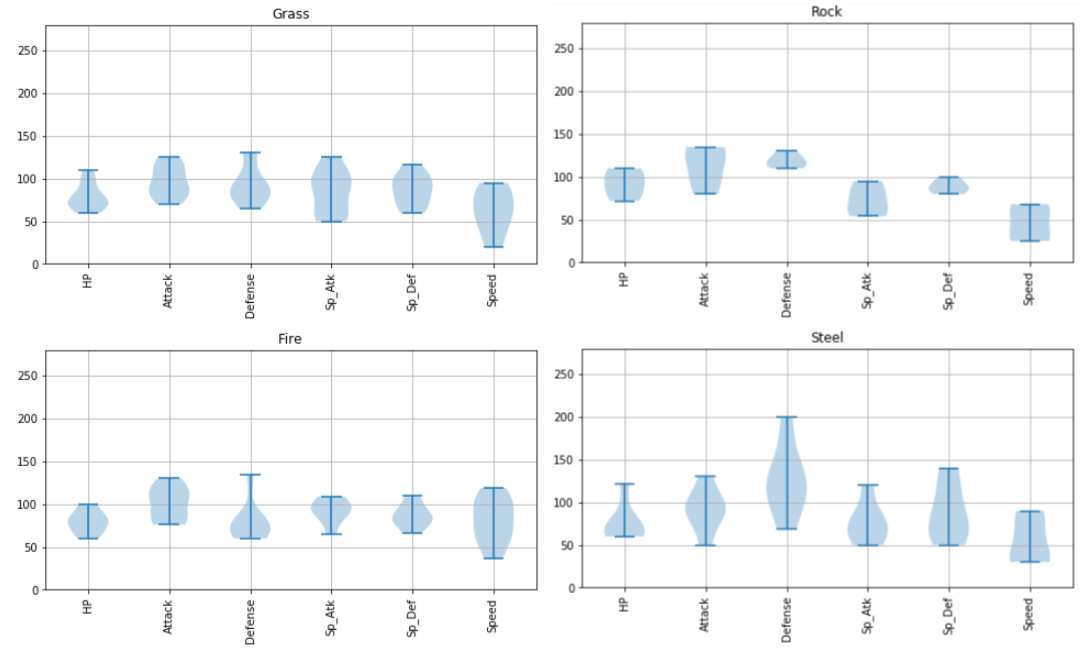
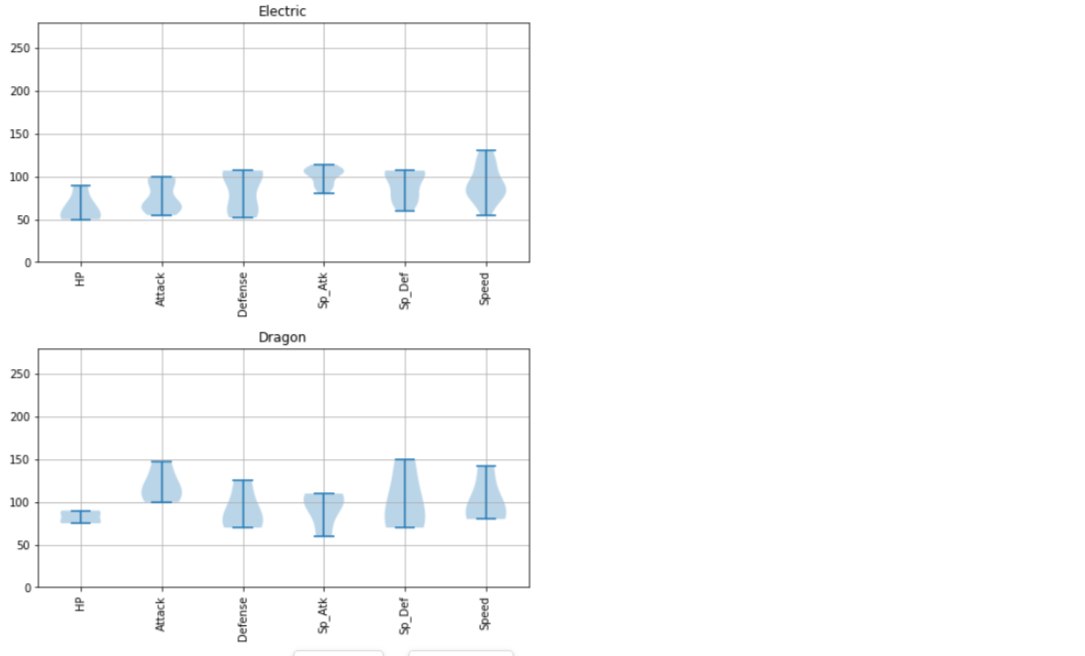 Psychic は攻撃力含め総合的に高いものがいるとか、Steel は防御力が高めだとか、Flying の能力分布は上位の方に偏っているとか、Dragon は意外と防御力が低めだとか、いろんな傾向が読み取れます。
Psychic は攻撃力含め総合的に高いものがいるとか、Steel は防御力が高めだとか、Flying の能力分布は上位の方に偏っているとか、Dragon は意外と防御力が低めだとか、いろんな傾向が読み取れます。
ちょっと脱線していたらごめんなさい。
ポケモン選択
さてこれからポケモン選択を行っていくのですが、忘れてはいけないタイプ相性です。
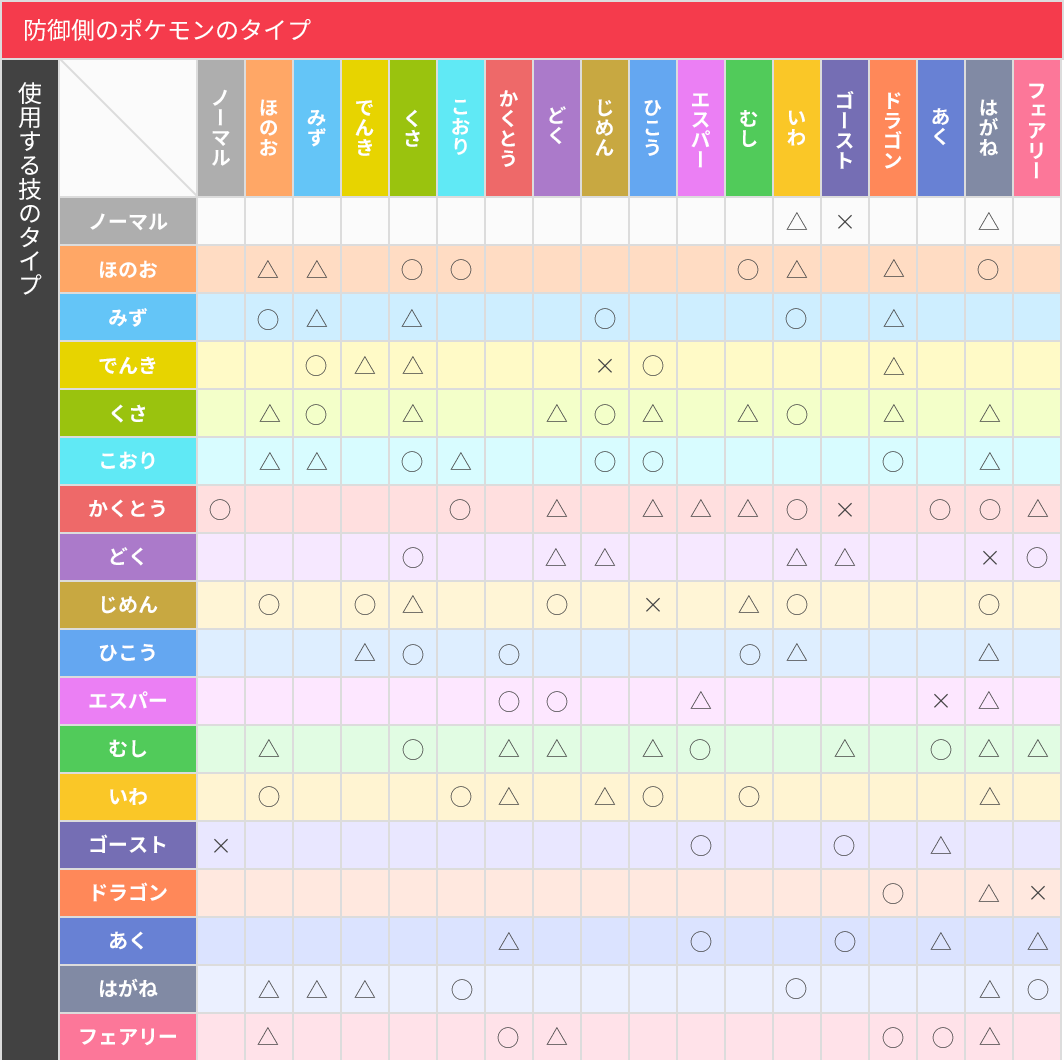 当たり前だけど、水タイプは炎タイプへ効果抜群!
当たり前だけど、水タイプは炎タイプへ効果抜群!
なりたい自分になれる
スキルアップならUdemy
私も利用し、高収入エンジニアになったのよ。未経験から機械学習、データサイエンティスト、アプリ開発エンジニアを目指せるコンテンツが多数あります。優秀な講師が多数!割引を利用すれば1,200円〜から動画購入可能です。!





