こんにちは、@Yoshimiです。
前回、「YahooのYahoo! Finance APIを利用して株価を取得する」で、Yahoo! Finance APIの使い方を紹介しました。
今回は、Yahoo! Finance APIを利用し、株価予測をするモデルを作成する方法を紹介します。
Yahoo! Finance APIで株価予測するモデルを作成してみよう
データ取得
株価取得の方法は前回の「YahooのYahoo! Finance APIを利用して株価を取得する」を参考にしてください。今回は少しデータ数を多くしたいので直近10年間の株価データでモデルを作成していきます。
from yahoo_finance_api2 import share
from yahoo_finance_api2.exceptions import YahooFinanceError
import pandas as pd
code = 3323 #ターゲット
S_year = 10
S_day = 1
# 目的変数を作成する
def kabuka():
company_code = str(code) + '.T'
my_share = share.Share(company_code)
symbol_data = None
try:
symbol_data = my_share.get_historical(share.PERIOD_TYPE_YEAR,
S_year,
share.FREQUENCY_TYPE_DAY,
S_day)
except YahooFinanceError as e:
print(e.message)
sys.exit(1)
# 株価をデータフレームに入れている
df_base = pd.DataFrame(symbol_data)
df_base = pd.DataFrame(symbol_data.values(), index=symbol_data.keys()).T
df_base.timestamp = pd.to_datetime(df_base.timestamp, unit='ms')
df_base.index = pd.DatetimeIndex(df_base.timestamp, name='timestamp').tz_localize('UTC').tz_convert('Asia/Tokyo')
#df_base = df_base.drop(['timestamp', 'open', 'high', 'low', 'volume'], axis=1)
#df_base = df_base.rename(columns={'close':company_code + '対象'})
#df_base = df_base[:-1] #一番最後の行を削除
df_base = df_base.reset_index(drop=True)
return company_code, df_base
result = kabuka()
print(str(result[0]), result[1].shape)
# データフレームへもどす
df_base = result[1]
df_base.head()
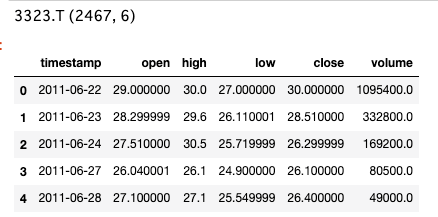
3323.T (2467, 6) と2467レコード、6カラムのデータが取得できました。
前処理:予測するためのデータ加工
高い精度を出すためには予測に必要なデータが揃っていることが大切です。逆に無駄なデータがある(次回ブログテーマと考えています。)と精度が下がってしまうなどという場合もあるので注意が必要です。今回は、予測モデルを作成するがテーマなので、その部分は触れず進めていきます。
今回のデータは
- timestamp
- open
- high
- low
- close
- volume
の6カラムです。Yahoo! Finance APIのデフォルト取得カラムです。
さてさて、今回のデータから予測モデルを作成する流れは以下の通りです。
パッとみた感じ、株価に関係なさそうなデータとしてその日のtimestampは関係なさそうな気がするので、除外対象とします。timestampが予測に絶対不必要というわけではなく、ディープラーニングで時系列を扱う場合LSTMという時系列に強い処理方法もあるので覚えておくと良いです。今回のモデル作成では除外対象です。
曜日はどうでしょう?週明けの月曜は取引量が多いのかな?、週末の金曜日でも決済をする人が多そう(土日をまたぎたくない)という気になることがあればデータを揃えてあげる必要があります。というように、取得データ意外にも必要そうなデータがあるのであれば、一度データを整えます。
予測するにあたり、当日の株価を予測よりも明日の株価を予測する方は個人的にはあっている気がするのです。理由としては、アプリ開発にもつながるのですが、当日の株価を当日のデータを参照しながら予測するって市場が動いている限り、株価も変動しているので、どのタイミングのデータをとるの?とかなり難しいと思うのです。であれば、終値のデータもAPIでもってくることができるので前日までのデータを利用して、翌日の終値を予測することが現実的ではないかな〜???と思うのですよ。
▼こんなイメージです▼
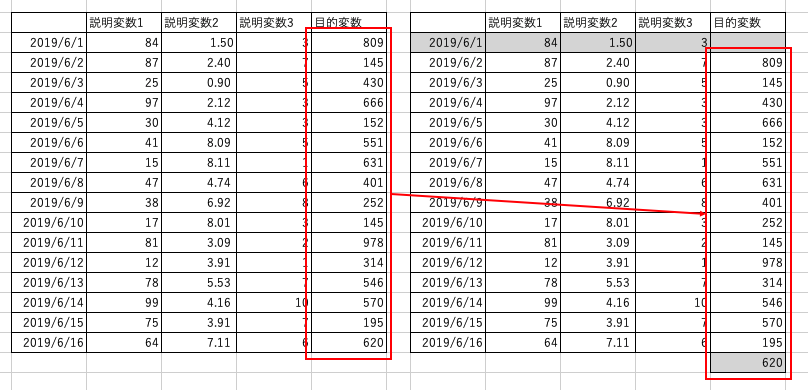 この辺りを処理にいれます。
この辺りを処理にいれます。
データが揃ったら、どのデータ(説明変数)でどの値を予測する(目的変数)のかをわけます。終値を予測するので、yにはcloseを代入しておきます。
が、しかし、私は予測する際に、元データにある目的変数になるデータはdropしてしまうので、先にyに抽出しておきます。[1:]で先頭行を削除です。
#説明変数:close y = df_base['close'][1:] y
目的変数を作成していきます。
モジュールdatetimeをimportし、曜日はtimestampから取得しています。
曜日を取得できた(day_of_weekに代入されている)ので、ダミー変数化を行います。
ダミー変数とは、数字ではないデータを数字に変換する手法のことです。 具体的には、数字ではないデータを「0」と「1」だけの数列に変換します。文字列では計算処理ができないので、計算できるように変換しましょうねというものです。pandasのget_dummiesを使います。
.shift()[1:]では、.shift()で全体を一行ずらします。そうすると、先頭行がNullになるので、そのNullを[1:]で削除します。
「え?これ意味あるの?」を思われるのですが、.shift()はレコード数を変えない性質があるので、例えば、1000レコードで.shift()を実行すると、1行下にずれるけどレコード数は1000のまま、ところてん方式で一行Nullがはいってきたというイメージです。yも[1:]で1行へらしているので、レコード数を合わせることをしております。
そのあとは、不要な絡むの削除をして、一旦、説明変数のデータフレームは完了です。
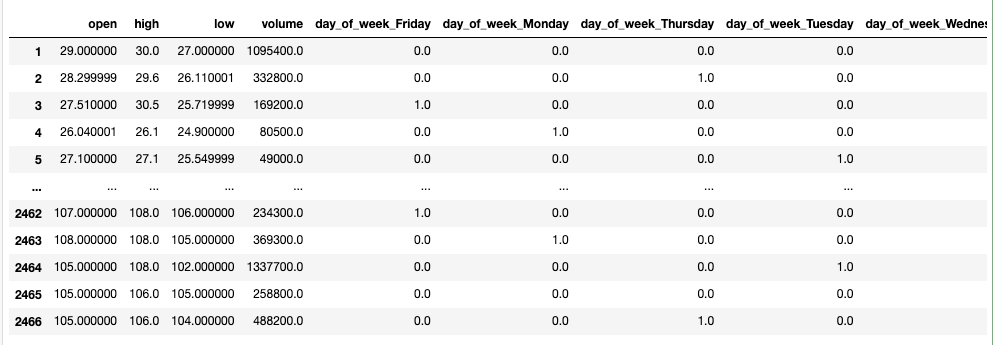
import datetime as dt # 曜日を足す df_base['day_of_week'] = df_base['timestamp'].dt.day_name() df_base # 曜日をダミー変数化 ohe_columns = ['day_of_week'] # pd.get_dummiesがone-hotエンコード、ダミー変数化 df_base = pd.get_dummies(df_base, dummy_na=True, columns=ohe_columns) #目的変数:timestamp,closeを削除 df_base = df_base.drop(['timestamp', 'close'], axis=1) # 予測モデルようDF X = df_base.shift()[1:] X
Xがデータフレームです。
モデル作成
目的変数と説明変数が完成したので、モデルを作成していきます。
データを見ると出来高、高値との差ってすごいありますよね?当たり前だと人間は思うのですが、機械はそれを当たり前だと思わないのです。では、どうするのか?世の中の数学者たちは標準化というデータを整形するということを編み出しています。
データを標準化すると、標準化したデータの平均は0に、分散(標準偏差も)は1になります。これにより、異なる項目のデータであってもその大小を比較できるようになります。
引用:統計学の時間 | 統計WEB
標準化の意味はわかったけど数式ってどうするの?と思う方もいるかと思いますが、Pythonでは標準化のモジュールも用意されているので問題ありません。
さて、ここからモデルをモデルを作成方法を紹介します。下記のコードをみてください。
#標準化する from sklearn.preprocessing import StandardScaler #データを切り分ける from sklearn.model_selection import train_test_split #利用するアルゴリズムを読み込む from sklearn.linear_model import LinearRegression,Ridge from sklearn.tree import DecisionTreeRegressor from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor #便利ツール from sklearn.pipeline import Pipeline #評価方法 from sklearn.metrics import r2_score
必要なモジュールを読み込みます。
| モジュール | 概要 |
|---|---|
| StandardScaler | 標準化してくれる |
| train_test_split | データフレームを訓練用とテストに分ける test_size=0.25だと、検証用に75%、テスト用に25%に分ける |
| LinearRegression、Ridge、DecisionTreeRegressor、RandomForestRegressor、GradientBoostingRegressor | アルゴリズムの種類 各説明割愛 |
| Pipeline | 複数の処理プログラムを直列に連結し、ある処理プログラムの出力が次の処理プログラムの入力となるようにし、複数の処理プログラムを並行処理させる |
| r2_score | 評価方法 完全に一致する場合に 1 となり、1 に近いほど精度の高い予測が行えている ※他多数あり、目的によって使い分けます。 |
データを検証用とテスト用にわけます。
# ホールドアウト(Xとyに切っていく)
X_train,X_test,y_train,y_test = train_test_split(X,
y,
test_size=0.25,
random_state=1)
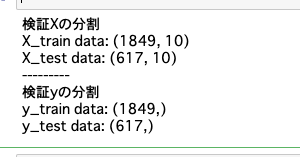
print('検証Xの分割')
print('X_train data:', X_train.shape)
print('X_test data:', X_test.shape)
print('---------')
print('検証yの分割')
print('y_train data:', y_train.shape)
print('y_test data:', y_test.shape)
pipeline処理でまとめて計算を行えるようにします。全体のイメージとしては私はfor文とlistが合体した感じと捉えています。
pipelines ={}で処理のための、listを作成します。'ols'や'ridge'がlistの項目になるイメージです。
# pipeline setting
pipelines = {
'ols': Pipeline([('scl',StandardScaler()),
('est',LinearRegression())]),
'ridge':Pipeline([('scl',StandardScaler()),
('est',Ridge(random_state=0))]),
'tree': Pipeline([('scl',StandardScaler()),
('est',DecisionTreeRegressor(random_state=0))]),
'rf': Pipeline([('scl',StandardScaler()),
('est',RandomForestRegressor(random_state=0))]),
'gbr1': Pipeline([('scl',StandardScaler()),
('est',GradientBoostingRegressor(random_state=0))]),
'gbr2': Pipeline([('scl',StandardScaler()),
('est',GradientBoostingRegressor(n_estimators=200,
random_state=0))])
}
各アルゴリズムで精度を確認してみます。
for文で各アルゴリズムを検証していることはお分かりでしょうか?
pipeline.fit(X_train, y_train)ですね。
# build and evaluate
scores = {}
for pipe_name, pipeline in pipelines.items():
pipeline.fit(X_train, y_train)
#trainデータで学習
scores[(pipe_name,'train')] = r2_score(y_train, pipeline.predict(X_train))
#テストデータを予測
scores[(pipe_name,'test')] = r2_score(y_test, pipeline.predict(X_test))
pd.Series(scores).unstack()
予測結果のアウトプットです。

う〜ん・・・検証とテストで高スコアすぎるんですよね。test列が、trainで学習したモデルをもとに、testデータセットで精度を確認しております。その制度が99%って・・・最強すぎやありませんか???怪しいですよね。
過学習なイメージを持ちます。ほぼ精度100%ですからね。
最後に
どうでしょうか?
予測モデルを作成すするだけであれば、ライブラリが整っているので、難しい計算式を記述する必要がないのです。(めっちゃ便利な時代です!)RandomForestRegressorでは、どんな処理方法で判定してるのかくらいは大雑把でいいので押さえておくと良いと思います。
多くのアルゴリズムの中から最適なアルゴリズムに出会うまでも多くの時間を費やしますし、さらにそこからパラメータ(計算粒度)を探すなどが機械学習エンジニアのあるべき姿なのかなとおも思っています。(パラメータ探しもモジュール追加で機械がやってくれるんですけどね・・・)
いろいろなデータが世に落ちているので、気になるデータでモデル作成してみてください。
私は当分の間、株価データを利用し、どうやったら自動的に儲かるのかを考えていきたいと思います。
なりたい自分になれる
スキルアップならUdemy
私も利用し、高収入エンジニアになったのよ。未経験から機械学習、データサイエンティスト、アプリ開発エンジニアを目指せるコンテンツが多数あります。優秀な講師が多数!割引を利用すれば1,200円〜から動画購入可能です。!