こんにちは、@Yoshimiです。
Pythonの勉強を日々しています。今回は、求人を掲載している企業の情報をPythonで取得(スクレイピング)することに挑戦したいと思います。
スクレイピングには、seleniumとBeautifulsoupが有名ですが、今回は、seleniumを利用していきます。
目次
求人掲載企業の情報をPythonで取得(スクレイピング)する【マイナビ】
今回は、【マイナビ 新卒】に掲載れている企業の情報をスクレイピングで取得していきます。
マイナビの情報をスクレイピングするにも、情報量が多すぎるのである程度絞っていきます。条件は以下の通りにします。
- 対象サイト:マイナビ新卒2021
- 対象業種:ソフトウェア・情報処理・ネット関連
- 取得情報:会社名、本社情報、E-mail
情報を確認すると2725社が対象となります。
seleniumでスクレイピングを行う流れ
スクレイピングを行う前に一連の流れを確認しておきます。私が考えた流れは以下の通りです。
1.リンク一覧を取得する
- 対象業種で一覧になっている企業の詳細ページリンクを取得する
- 取得したリンクをリスト化する
- ページネーションで「次のページ」に進む
- 1,2の繰り返し
- ページがなくなったら終了
その次に、
2.取得したリンク一覧をもとに詳細ページへ遷移し、任意のデータを取得する
- データを格納するデータフレームを作成
- 取得したリンクリストを元に、詳細ページ情報へ遷移
- 詳細ページないの任意のデータを取得し、データフレームへ格納する
- 2〜3の繰り返し
という流れです。
seleniumでスクレイピングコード
seleniumをつかってブラウザを立ち上げてスクレイピングの準備をします。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
import pandas as pd
from time import sleep
options = Options()
options.add_argument('--headless')
browser = webdriver.Chrome('chromedriverのあるパス',options=options)
pageURL = 'https://job.mynavi.jp/21/pc/search/query.html?IC:40,41,42/LICM:1/func=PCTopQuickSearch'
browser.get(pageURL)
sleep(3)
基本的なモジュールをインポートします。
seleniumでは、ブラウザを立ち上げて処理していくのが一般的のようですが、ブラウザを立ち上げることなく処理することが可能です。--headlessを使います。
options = Options()
options.add_argument(”)
browser=では、chromedriverのパスを指定してください。pageURL=に絶対パス(サイトのURL)を入れ、このページを起点とします。「次の100社」をクリックし、ページ遷移します。
 ページ遷移後のURLを確認すると以下のようなURLになっています。
ページ遷移後のURLを確認すると以下のようなURLになっています。
https://job.mynavi.jp/21/pc/corpinfo/searchCorpListByGenCond/doNextPage
?=page(No)など番号で管理されているのであれば、URL取得のイメージはつきやすいのですが、上記URLでのページ遷移の場合、URLでの管理ができません。ですので、「次の100社」をクリックして次ページに遷移する処理を行います。
ページネーション分の企業一覧リンクを取得します。
# リンク一覧を格納するリストを準備
elem_urls=[]
# while で find_element_by_link_text が breakするまでループ
while True:
elems = browser.find_elements_by_css_selector(".boxSearchresultEach h3 a")
for elem in elems:
elem_urls.append(elem.get_attribute("href"))
# 次へをクリックしページ遷移する
try:
next_button = browser.find_element_by_link_text('次の100社')
next_button.click()
sleep(3)
except Exception:
#browser.quit()
break
print('会社ページ数:', len(elem_urls))
elem_urls=[]でリンク一覧を格納する、空のリストを作っておきます。次が肝です。ループ処理はfor文を多用すると思いますが、今回はwhile文で行います。条件は、「次の100社」をクリックできなくなるまで処理するからです。
elemsに、ページないの「h3タグないaタグ」の情報が格納されます。
for文で、elemsに格納された情報のhrefを取得し、elem_urlsに追加していきます。これで1ページ分の企業ページへのリスト一覧が作成されました。
next_button = browser.find_element_by_link_text(‘次の100社’)へ指定し、next_button.click()でクリックし、ページ遷移します。ページ遷移ができたら、ページないのaタグ情報が必要になりますので、elems = から処理が走ります。
try:〜except Exception:部分は、ページ遷移ができなかった場合、「break」する。つまり、このwhileの処理を終了するというコードです。
print(‘会社ページ数:’, len(elem_urls))で確認すると企業ページへのリンク一覧2725件が取得できました。
企業詳細ページの任意の情報を取得し、データフレームに格納していきます。
# 列を指定し、空のデータフレーム作成し、代入
cols=['会社名','本社','E-mail']
df = pd.DataFrame(index=[], columns=cols)
for i in elem_urls:
browser.get(i)
# 会社名取得
comp_tit = browser.find_element_by_class_name("heading1-inner")
comp_tit = comp_tit.find_element_by_tag_name("h1").text
# 本社住所
comp_add = browser.find_element_by_id("corpDescDtoListDescText50").text
# E-mail
try:
comp_email = browser.find_element_by_id("corpDescDtoListDescText130").text
except NoSuchElementException:
comp_email = ''
df=df.append({'会社名':comp_tit,'本社':comp_add,'E-mail':comp_email}, ignore_index=True)
print(len(df))
データフレームに格納されているデータ数2725件が確認できました。
df.head()
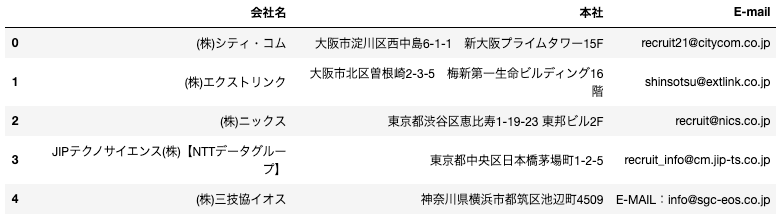
Pythonとseleniumを利用し、目的の情報を取得することができました。
スクレイピングの注意点
スクレイピング関連の記事で見かけるのは「スクレイピングは違法」というのを目にすることがあります。サイト自体の著作権、利用規約への抵触、サーバーへの過度なアクセスによるユーザー・運用者への影響(最悪な場合サービスストップしてしまう)などあるため、基本的には「自動でのスクレイピングを良し(もちろん手動での頻繁なスクレイピング)」としているサービスはないはずです。
スクレイピングが違法にならないためにするには、「利用規約」をしっかり確認しましょう。「利用目的」「スクレイピングの対象」「アクセス制限の遵守」に注意を払っておくことが必要です。
最後に
今回、seleniumでURLからページNoを取得することができず「次へ」「次のページへ」「NEXT」というページ遷移をクリアするために、
next_button = browser.find_element_by_link_text(‘次の100社’)
next_button.click()
を利用しました。
seleniumの関数もまだまだ勉強が必要なので、どんなサイトからでも自由に取得できるよう精進します。
なりたい自分になれる
スキルアップならUdemy
私も利用し、高収入エンジニアになったのよ。未経験から機械学習、データサイエンティスト、アプリ開発エンジニアを目指せるコンテンツが多数あります。優秀な講師が多数!割引を利用すれば1,200円〜から動画購入可能です。!




