
こんにちは、@Yoshimiです。
機械学習を勉強しているみなさんがチャレンジしているKaggle tutorial Titanicにチャレンジしてみました。
初心者にとっては、Kaggle tutorial Titanicはデータ分析を練習するには非常に良い課題です。Kernel(カーネル)を参考にしながら、さまざまなスキルをつけていくことができます。
先人のKernelを参考(ほぼコピペ)にしつつ「0.82297」になったので備忘録としてまとめておきます。
目次
kaggleのTitanic課題とは
Titanic: Machine Learning from Disaster
沈没してしまったTitanic号ですが、どういう属性の方々が生存できたのか?というのを課題になっております。ざっくり説明するとこんな感じです。
生存したのか?生存しなかったのか?と生存予測を判別するので、分類課題となります。
データ説明変数
- PassengerID:乗客ID
- Survived:生存結果 (1: 生存, 2: 死亡)
- Pclass:乗客の階級 1が一番位が高いそう
- Name:乗客の名前
- Sex:性別
- Age:年齢
- SibSp:兄弟、配偶者の数
- Parch:両親、子供の数
- Ticket:チケット番号
- Fare:乗船料金
- Cabin:部屋番号
- Embarked:乗船した港「Cherbourg」「Queenstown」「Southampton」
モジュールの読み込み、データの読み込み
人気モジュールセットを読み込みます。
import pandas as pd import numpy as np # 学習モデル from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split # 評価指標 from sklearn.metrics import accuracy_score # google colabに外部ファイルをインポート from google.colab import files
uploaded = files.upload()
データの確認
カテゴリーデータにあるSex:性別とEmbarked:乗船した港はわかりやすいのでサクッとデータ変換(replace)しておきます。
train= pd.read_csv("titanic_train.csv").replace("male",0).replace("female",1).replace("S",0).replace("C",1).replace("Q",2)
test= pd.read_csv("titanic_test.csv").replace("male",0).replace("female",1).replace("S",0).replace("C",1).replace("Q",2)
データを確認してみます。
train.head()
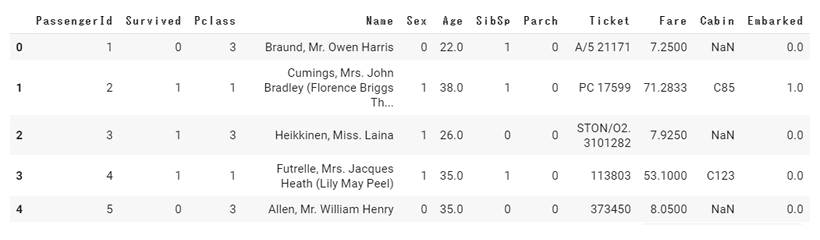
SexとEmbarkedが0,1,2の値に変換されています。これでデータ分析に使えるデータになりました。
データにはどんな型のデータがあるのかinfo()関数で確認します。
train.info()
 TicketとCabinが残るobject型であることが確認できました。
TicketとCabinが残るobject型であることが確認できました。
次は欠損値を確認してみます。
def missing_value_table(df):
null_val = df.isnull().sum()
percent = 100 * df.isnull().sum()/len(df)
missing_table = pd.concat([null_val, percent], axis=1)
missing_table_ren_columns = missing_table.rename(
columns = {0 : '欠損数', 1 : '%'})
return missing_table_ren_columns
print('train data')
print(missing_value_table(train))
print('-----------')
print('test data')
print(missing_value_table(test))
 train dataには「Age」「Cabin」「Embarked」に、test dataには「Age」「Cabin」の欠損値が含まれていることがわかりました。次から欠損値の処理、不要データ削除などの前処理(Data Clearing)に取り掛かります。
train dataには「Age」「Cabin」「Embarked」に、test dataには「Age」「Cabin」の欠損値が含まれていることがわかりました。次から欠損値の処理、不要データ削除などの前処理(Data Clearing)に取り掛かります。
データの前処理
前処理で代表的な処理として
- 欠損値の穴埋め
- カテゴリーデータの数値化
- 外れ値の処理
- 特徴量生成
を行います。
「外れ値の処理」はplotし可視化してチェックするとわかりやすいです。「特徴量生成」は統計のセンス、データの読み方などで気が付く・つかないで差が出てくると思っています。私にはまだまだなので頑張ります。
欠損値を穴埋めする
「Age」「Cabin」「Embarked」に欠損値があることが分かっているので、穴埋めを行ていきます。穴埋めにも「平均値」「中央値」「最頻値」など種類があるのでここもセンスが必要となります。
今回は
- Age:平均値
- Cabin:今は保留後程
- Embarked:平均値
で処理を行っていきます。
# 欠損値を穴埋めする train["Age"].fillna(train.Age.mean(), inplace=True) train["Embarked"].fillna(train.Embarked.mean(), inplace=True)
カテゴリーデータの処理
カテゴリ変数(カテゴリカルデータ、質的データ)をダミー変数に変換するには、pandas.get_dummies()関数を使う。One-Hotエンコーディングとも呼びます。
Name:乗客の名前
Nameは一見バラバラにみえるのですが、それでも特徴があることに気が付きます。それは「Mr、Mrs、Miss」などの敬称があることです。よく子供優先、女性優先という紳士のルールがあります。ということはこの「Mr、Mrs、Miss」の敬称(男性、女性、未婚・既婚など)も生存に関係があるかもしれないと考え継承で分類してみることにチャレンジします。
新しい変数「Salutation」を用意し、分類作業を行います。ちなみににSalutationは挨拶という意味らしいです。そして、今回は女性に対して使うMissとMrsがMsに統合されているそうです。
combine1 = [train]
for train in combine1:
train['Salutation'] = train.Name.str.extract(' ([A-Za-z]+).', expand=False)
for train in combine1:
train['Salutation'] = train['Salutation'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
train['Salutation'] = train['Salutation'].replace('Mlle', 'Miss')
train['Salutation'] = train['Salutation'].replace('Ms', 'Miss')
train['Salutation'] = train['Salutation'].replace('Mme', 'Mrs')
del train['Name']
Salutation_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
for train in combine1:
train['Salutation'] = train['Salutation'].map(Salutation_mapping)
train['Salutation'] = train['Salutation'].fillna(0)
少しコードをチェックしてみます。
Nameの前処理のゴールはNameをデータとして使えるようにするです。なので、数値化を目指します。
Nameの特徴といえば、Mlle、Msの他に、固有の呼び名があるようです。Drなどはわかりやすいですよね。そのような名称をグループ分けしていきます。
str.extract()は正規表現で分割するのに使います。
replace()は文字列(str)型のメソッドです。文字列を指定して置換することができます。Salutation_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5} はdict型とし、変換します。
Ticket:チケット番号
今度はTicketの処理は「先頭の文字」「文字列の長さ」で分けていきます。その後にそれらの文字を数字に直します。
for train in combine1:
train['Ticket_Lett'] = train['Ticket'].apply(lambda x: str(x)[0])
train['Ticket_Lett'] = train['Ticket_Lett'].apply(lambda x: str(x))
train['Ticket_Lett'] = np.where((train['Ticket_Lett']).isin(['1', '2', '3', 'S', 'P', 'C', 'A']), train['Ticket_Lett'], np.where((train['Ticket_Lett']).isin(['W', '4', '7', '6', 'L', '5', '8']), '0','0'))
train['Ticket_Len'] = train['Ticket'].apply(lambda x: len(x))
del train['Ticket']
train['Ticket_Lett']=train['Ticket_Lett'].replace("1",1).replace("2",2).replace("3",3).replace("0",0).replace("S",3).replace("P",0).replace("C",3).replace("A",3)
Cabin:部屋番号
for train in combine1:
train['Cabin_Lett'] = train['Cabin'].apply(lambda x: str(x)[0])
train['Cabin_Lett'] = train['Cabin_Lett'].apply(lambda x: str(x))
train['Cabin_Lett'] = np.where((train['Cabin_Lett']).isin([ 'F', 'E', 'D', 'C', 'B', 'A']),train['Cabin_Lett'], np.where((train['Cabin_Lett']).isin(['W', '4', '7', '6', 'L', '5', '8']), '0','0'))
del train['Cabin']
train['Cabin_Lett']=train['Cabin_Lett'].replace("A",1).replace("B",2).replace("C",1).replace("0",0).replace("D",2).replace("E",2).replace("F",1)
やっと一通り数値化できたと思うので、trainをチェックしてみます。
train.head()
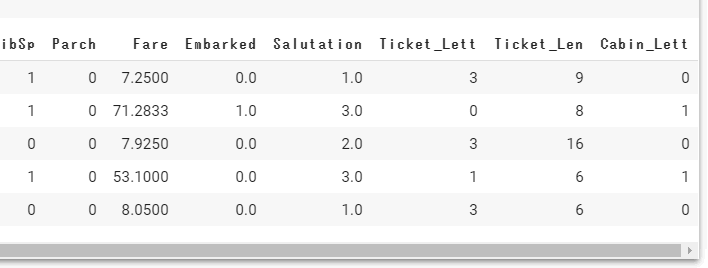
制度を高めるために新たな変数を追加していきます。FamilySizeとIsAloneです。
考えると気が付くかもしれませんが、「一緒に乗船している人数によって生存に大きく差が出る」からです。
ここまででまだ使われていないものはPclass、SibspとParchです。Pclassは何等級のところに乗っていたかを表すものなので、そのまま利用できます。Sibspは乗っていた夫婦と兄弟の人数を表したものです。Parchは乗っていた親と子供の人数を表したものです。よってSibsp+Parch+1がFamilySizeとなります。また、FamilySizeが1だとIsAlone一人で乗っているかどうかが1となります。
train["FamilySize"] = train["SibSp"] + train["Parch"] + 1
for train in combine1:
train['IsAlone'] = 0
train.loc[train['FamilySize'] == 1, 'IsAlone'] = 1
これでやっとtrainの処理は終わりました。次に、trainのデータを機械学習にかけるために加工します。はじめにtrainの値だけを取り出し、次にそれを正解データと学習用のデータに分けます。
train_data = train.values X = train_data[:, 2:] # Pclass以降の変数 y = train_data[:, 1] # 正解データ
testデータの加工
test["Age"].fillna(train.Age.mean(), inplace=True)
test["Fare"].fillna(train.Fare.mean(), inplace=True)
combine = [test]
for test in combine:
test['Salutation'] = test.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
for test in combine:
test['Salutation'] = test['Salutation'].replace(['Lady', 'Countess','Capt', 'Col',\
'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
test['Salutation'] = test['Salutation'].replace('Mlle', 'Miss')
test['Salutation'] = test['Salutation'].replace('Ms', 'Miss')
test['Salutation'] = test['Salutation'].replace('Mme', 'Mrs')
del test['Name']
Salutation_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
for test in combine:
test['Salutation'] = test['Salutation'].map(Salutation_mapping)
test['Salutation'] = test['Salutation'].fillna(0)
for test in combine:
test['Ticket_Lett'] = test['Ticket'].apply(lambda x: str(x)[0])
test['Ticket_Lett'] = test['Ticket_Lett'].apply(lambda x: str(x))
test['Ticket_Lett'] = np.where((test['Ticket_Lett']).isin(['1', '2', '3', 'S', 'P', 'C', 'A']), test['Ticket_Lett'],
np.where((test['Ticket_Lett']).isin(['W', '4', '7', '6', 'L', '5', '8']),
'0', '0'))
test['Ticket_Len'] = test['Ticket'].apply(lambda x: len(x))
del test['Ticket']
test['Ticket_Lett']=test['Ticket_Lett'].replace("1",1).replace("2",2).replace("3",3).replace("0",0).replace("S",3).replace("P",0).replace("C",3).replace("A",3)
for test in combine:
test['Cabin_Lett'] = test['Cabin'].apply(lambda x: str(x)[0])
test['Cabin_Lett'] = test['Cabin_Lett'].apply(lambda x: str(x))
test['Cabin_Lett'] = np.where((test['Cabin_Lett']).isin(['T', 'H', 'G', 'F', 'E', 'D', 'C', 'B', 'A']),test['Cabin_Lett'],
np.where((test['Cabin_Lett']).isin(['W', '4', '7', '6', 'L', '5', '8']),
'0','0'))
del test['Cabin']
test['Cabin_Lett']=test['Cabin_Lett'].replace("A",1).replace("B",2).replace("C",1).replace("0",0).replace("D",2).replace("E",2).replace("F",1).replace("G",1)
test["FamilySize"] = train["SibSp"] + train["Parch"] + 1
for test in combine:
test['IsAlone'] = 0
test.loc[test['FamilySize'] == 1, 'IsAlone'] = 1
test_data = test.values
X_test = test_data[:, 1:]
やっとtrain、testのデータクリーニングが終わりました。kaggleには、上位1%を取るかたはこれ以上の素晴らしい前処理方法を実施していると思いますが、今のところこんな感じで勘弁してくださいとのことです。
ここからがメインの学習タイムです。今回は、RandomForestClassifierを使ってみます。他の記事でも結構いい評価が出ているという記事があるので問題ないと思います。
modelという箱をつくり、そこで学習させます。学習させるには、(説明変数, 目的変数)の順で代入します。その後、predict()関数を使い、予測したい説明変数のデータをあてこみます。
model=RandomForestClassifier() model.fit(X, y) Y_pred = model.predict(X_test)
提出ファイルを作成します。
predict_result_data.csvに書き込みます。
import csv
with open("predict_result_data.csv", "w") as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow(["PassengerId", "Survived"])
for pid, survived in zip(test_data[:,0].astype(int), Y_pred.astype(int)):
writer.writerow([pid, survived])
kaggleへ提出されて結果はどうだったでしょうか?0.82297は出ましたか?「おいおい、違うじゃねーか」と怒っている方もいるかもしれませんが、実は、RandomForestClassifierには多数パラメータを設定する箇所があり、ランダムで生成されるされる部分もあるため、学習結果が毎回変わり、精度も少なからず影響を受けているというものです。
このパラメータを調整するのが機械学習エンジニアの実力の見せ所となります。なるようです。
パラメータ探索
機械学習モデルのハイパーパラメータを自動的に最適化してくれるというありがたい機能Grid search(グリッドサーチ)があります。ですが、基本的に時間がかかるのと複数の探索方法をjupyter notebookで探索するとkernel errorに起こりやすいというのが特徴です。
初回はmodelで箱を作成しましたが、model02で新しい箱を準備します。
model02=RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=25, max_features='auto', max_leaf_nodes=None,
min_samples_leaf=1, min_samples_split=15,
min_weight_fraction_leaf=0.0, n_estimators=51, n_jobs=4,
oob_score=False, random_state=0, verbose=0, warm_start=False)
メインで調整していくのは「n_estimators」「min_samples_split」「max_depth」です。random_stateは指定しないと毎回学習がかわるので適当な値を固定で指定します。非常に骨の折れる作業ですが、面白いでのチャレンジするのもありです。
Y_pred02と新たに作成します。
model02=RandomForestClassifier() model02.fit(X, y) Y_pred02 = model02.predict(X_test)
import csv
with open("predict_result_data02.csv", "w") as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow(["PassengerId", "Survived"])
for pid, survived in zip(test_data[:,0].astype(int), Y_pred02.astype(int)):
writer.writerow([pid, survived])
predict_result_data02.csvが作成されるので、kaggleに提出してみましょう。
本来、データクリーニングは説明変数と目的変数の関係を可視化したりし、説明変数の調整を行うことで、どんな特徴量を作成すべきかも把握でき、より精度が高くなります。
なりたい自分になれる
スキルアップならUdemy
私も利用し、高収入エンジニアになったのよ。未経験から機械学習、データサイエンティスト、アプリ開発エンジニアを目指せるコンテンツが多数あります。優秀な講師が多数!割引を利用すれば1,200円〜から動画購入可能です。!




