今回は、機械学習のアルゴリズムの一つであるサポートベクターマシン(SVM)を少し覗いてみて、実装します。
サポートベクターマシン(SVM)
SVMとはサポートベクターマシン(Support Vector Machine)の略で、教師ありの機械学習アルゴリズムです。
- 分類:SVC(Support Vector Classification)
- 回帰:SVR(Support Vector Regression)
の分析を行うことが可能です。
クラスを明確に分けるために「マージン最大化」を行い、境界線をひきます。
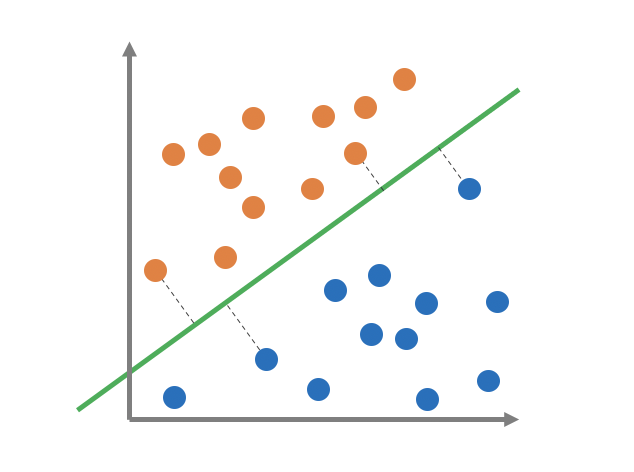
上図で黒の点線がマージン最大化となるような線のことです。
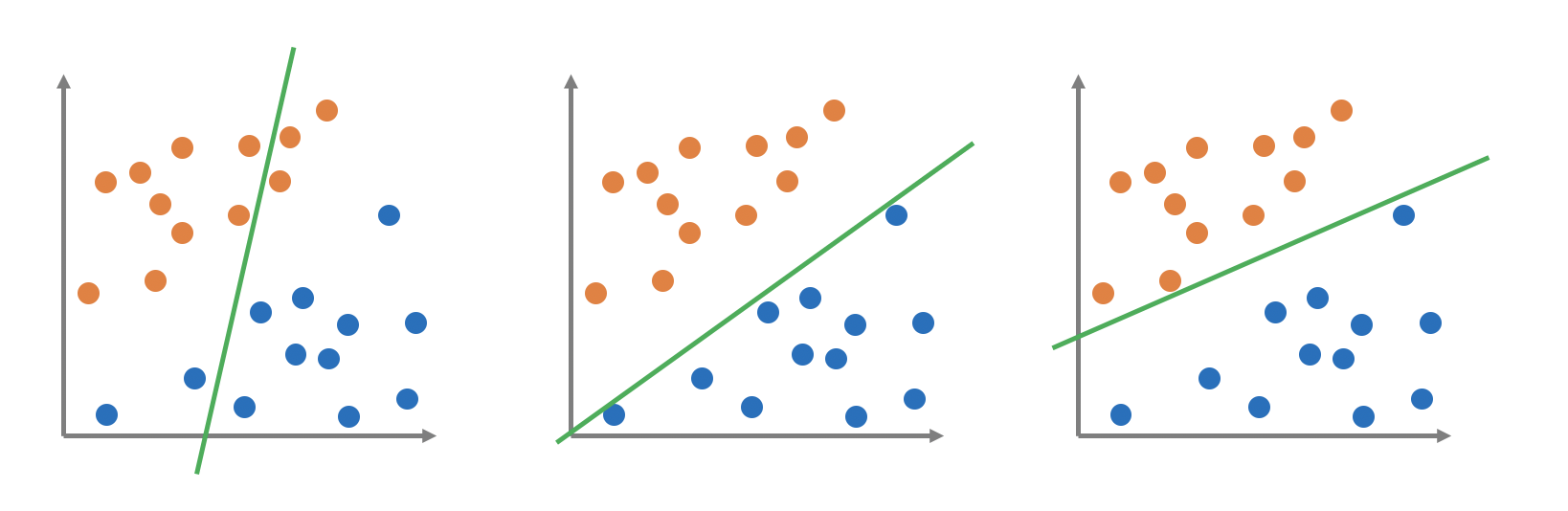
下図ではクラス分けできていない線、マージン最大化できていない線の例です。
特徴としては、少ない教師データで高い汎化性能がだせます。計算も早く過学習も起きにくく、非線形な識別をするための実装も容易ということでなんでもディープラーニングが登場する前までは最強説があったようです。
ただ、データがばらついていたり偏っていたりすると、計算量が膨大になったりと学習が非常に非効率なため、データサンプル数が多い場合は、メモリ使用量や実行において難しくなるというデメリットがあります。なんとなく時代を感じますよね。
サポートベクターマシン(SVM)を実装する
機械学習のチュートリアルでよく使われているアヤメのデータセットを利用してモデル構築していきます。

アヤメの品種のSetosa Versicolor Virginicaの3品種に関する150件のデータが入っています。別記事に詳細はまとめたのでチェックしてみてください。
データセットには以下の4つの特徴量があります。
- Sepal Length(がく片の長さ)
- Sepal Width(がく片の幅)
- Petal Length(花びらの長さ)
- Petal Width(花びらの幅)
正解ラベルは以下の3つです。
- 0: Setosa
- 1: Versicolor
- 2: Versinica
流れとしては、4つの特徴量を評価し、花の品種を3つのうちに分類するという感じです。
実装してみる
Irisのデータを確認しながらサポートベクターマシンを実装していきたいと思います。
import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn import datasets, model_selection, svm, metrics # Irisの測定データの読み込み iris = datasets.load_iris() print(type(iris)) print(iris.keys())
dict_keys([‘data’, ‘target’, ‘target_names’, ‘DESCR’, ‘feature_names’, ‘filename’])
datasets.load_iris()で読むと、seabornとは違い、辞書ライクなデータとして受け取れます。
4つの特徴量と分類ラベルをそれぞれpandasのDataFrameとSeriesとして格納します。
# 特徴量
iris_data = pd.DataFrame(data=iris.data, columns=iris.feature_names)
#分類ラベル
iris_label = pd.Series(data=iris.target)
print('='*10)
print(iris_data.head())
print('='*10)
print(iris_label.head())
print(iris_data.shape)
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
==========
0 0
1 0
2 0
3 0
4 0
dtype: int64
(150, 4)
学習用とテスト用に分割します。
model_selection.train_test_split()では、モジュールがいい感じに分割してくれます。デフォルトのパラメータではtest_size=0.25となっており、75%と25%での分割です。
data_train, data_test, label_train, label_test = model_selection.train_test_split(iris_data, iris_label)
print(data_train.head())
print('='*10)
print(label_train.head())
print('='*10)
print(len(data_train), len(data_test))
135 7.7 3.0 6.1 2.3
4 5.0 3.6 1.4 0.2
37 4.9 3.6 1.4 0.1
142 5.8 2.7 5.1 1.9
55 5.7 2.8 4.5 1.3
==========
135 2
4 0
37 0
142 2
55 1
dtype: int64
==========
112 38
学習用が112件、テスト用が38件に分割されました。
サポートベクターマシンで学習します。
clf = svm.SVC()
clf.fit(data_train, label_train)
predict = clf.predict(data_test)
print(type(predict))
print('予測結果:',predict)
予測結果: [0 2 1 2 0 0 2 1 0 0 1 1 0 2 2 1 0 1 1 1 0 2 2 1 0 2 1 0 0 0 0 0 0 1 0 0 1
0]
予測結果が出ましたので、結果を確認します。どのくらいの正解率 (Accuracy)だったでしょうか?ちなみに、正解率 (Accuracy)とは「本来ポジティブに分類すべきアイテムをポジティブに分類し、本来ネガティブに分類すべきアイテムをネガティブに分類できた割合」を示し、以下の式で表されます。
Accuracy = (TP + TN) / (TP + TN + FP + FN)
です。
ac_score = metrics.accuracy_score(label_test, predict) print(ac_score)
97.36%と高い正解率です。
学習用とテスト用に分割される際の割合やデータによってこの値は変わってきます。この検証を何回も実施し、平均をとるという検証の方法もありますので頭の片隅に入れておいてもいいかもしれません。
実験してみる
clfというモデルができました。
では、このモデルに新しいデータを追加してどの品種に分類されるか確認してみます。
print(clf.predict([[1.5, 4.5, 5.8, 0.2], [3.0, 3.6, 3.4, 0.4], [5.9, 3.8, 5.1, 2.8]]))
上の様なデータで予測したところ[1 ,1, 2]という分類になりました。
あとは、このデータに品種名を照らし合わせたりすれば、予測アプリ完成です。
最後に
SVMのライブラリを使用することで非常に簡単に分類ができました。分類は多くの分野で利用されていいます。
- テキスト分類(スパムメールなど)
- 数字認識(手書き文字)
- 顔検出・認識(顔認証システム)
などです。
SVMは線形分類という弱点はあたのですが、実は非線形分類も可能です。その場合、「カーネル関数」を使って対応します。
まだまだ奥が深いSVM。次回は、カーネル関数を少しまとめてみたいと思います。
なりたい自分になれる
スキルアップならUdemy
私も利用し、高収入エンジニアになったのよ。未経験から機械学習、データサイエンティスト、アプリ開発エンジニアを目指せるコンテンツが多数あります。優秀な講師が多数!割引を利用すれば1,200円〜から動画購入可能です。!





