
こんにちは、@Yoshimiです。
データ分析の練習としてSIGNATEの練習問題に取り組んでみたので備忘録として残しておきます。ランキングは温かい目で見てください。
今回チャレンジするのは「自動車の走行距離予測」です。
目次
データ概要
課題:
自動車の属性データからガソリン1ガロンあたりの走行距離を予測するモデルを作成していただきます
ということで、回帰問題になります。
どのようなデータが存在するのかチェックしてみます。
| カラム | ヘッダ名称 | データ型 | 説明 |
|---|---|---|---|
| 0 | id | int | インデックスとして使用 |
| 1 | mpg | float | ガソリン1ガロンあたりの走行距離(mile par gallon の略) |
| 2 | cylinders | varchar | シリンダー |
| 3 | displacement | float | 排気量 |
| 4 | horsepower | float | 馬力 |
| 5 | weight | float | 重量 |
| 6 | acceleration | float | 加速度 |
| 7 | model year | varchar | 年式 |
| 8 | origin | varchar | 起源 |
| 9 | car name | varchar | 車名 |
私は車にあまり興味がないのですが、ゲームのクオリティをみたときは少し感動したことを覚えています。車は消耗品の塊みたいなイメージがあるので、使えば使うほど劣化していくことを考えると何となく走行距離に関係する特徴量も想像がつきます。なぜ、走行距離なのか?ですが、走行距離が多ければ、タイヤも摩耗することが考えられるので、中古査定の時に金額に関わってくるのかなと。だから走行距離が気になるわけです。
モジュール・データの読み込み
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV
# 評価手法
from sklearn.metrics import r2_score
#データの読み込み
train = pd.read_csv('car_train.tsv', delimiter='\t')
test = pd.read_csv('car_test.tsv', delimiter='\t')
sample = pd.read_csv('car_sample_submit.csv', header=None)
今回、TSVファイルなのでdelimiter='\t'として読み込みます。
データの確認をする
データ数、カラム数をチェックします。
print('train data:', train.shape)
print('test data:', test.shape)
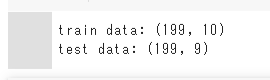
データ199あり、説明変数(特徴量)はmpgを除くと9あります。
データの一部をチェックしてします。
train.head()
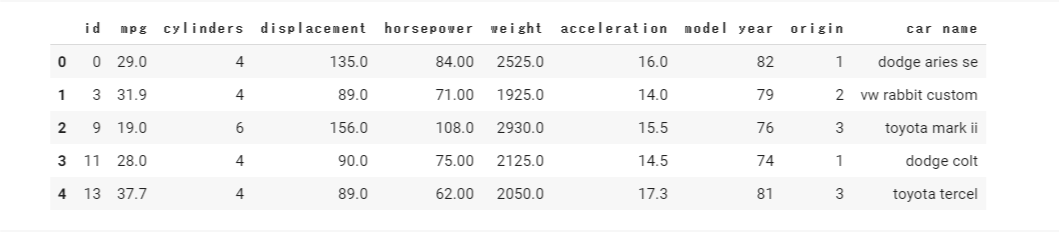
car nameがテキストになっております。object型でしょう。必要であれば数値化し、モデル構築に利用します。他は問題なさそうです。
欠損値も確認しておきましょう。欠損値があるようであれば、平均値、中央値、最頻値などで埋める処理が必要です。
print('train:', train.isnull().sum())
print('test:', test.isnull().sum())
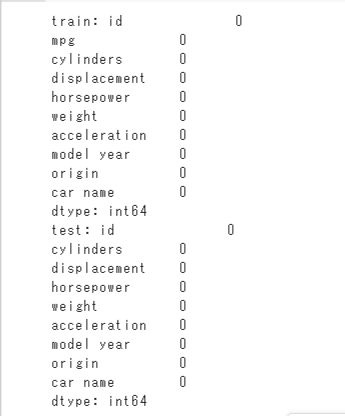 欠損値はなさそうです。
欠損値はなさそうです。
データの方をチェックします。
train.info()
ん??horsepowerがobjectになっております。head()で確認した際は、float型でしたが、もしかしたらどこかにfloat型以外のデータがあり、object型として認識されているのかもしれません。この不明なでデータを処理する必要があります。
データクリーニング・前処理
さて、ここがデータサイエンティストの見せ場の前処理です。
- 欠損値処理
- ダミー変数化
- 外れ値、不要なデータの削除
- 特徴量生成
がメインとなります。
外れ値の処理は実際、plot図を確認し、該当するようなデータがあれば処理を行っていきます。特徴量生成は関係性を確認し、新たに特徴量を自ら作るというものです。
欠損値
isnull().sum()で確認したところ、欠損はなかったので処理は不要
ダミー変数化
horsepowerがobjectになっていたのでデータの確認をします。すると?があることが発覚。どのくらいのデータがあるのか確認します。
# ?の個数を確認する print(train[train['horsepower'] == '?'])
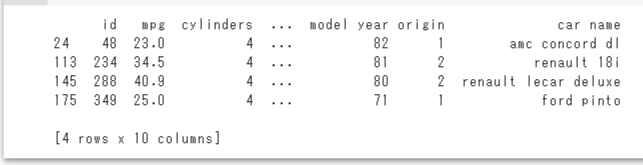 4つのでーががヒットしました。このデータを処理するのですが、
4つのでーががヒットしました。このデータを処理するのですが、np.nanで扱い、その後に平均値で埋めていきます。
train['horsepower'] = train.replace('?', np.nan)
train['horsepower'] = train['horsepower'].fillna(train['horsepower'].mean())
これでobjectがint64になりました。
同じ工程をtestデータでも行います。
test['horsepower'] = test.replace('?', np.nan)
test['horsepower'] = test['horsepower'].fillna(test['horsepower'].mean())
不要データの削除
計算には不要なデータを取り除いていきます。id、car nameを取り除きます。X_****に代入し、計算用データセットを作成します。
その処理の前に、目的変数を作成しておきます(yがdropされる前に抽出します)。今回の目的変数は、mpgなので、mpgをyへ代入しておきます。
y = train['mpg'] X_train = train.drop(['id', 'mpg', 'car name'], axis=1) X_test = test.drop(['id', 'car name'], axis=1)
データクリーニング・前処理が一通り終わったと思います。もちろん、相関図、箱ひげ図などを十分に活用してより素晴らしいデータを作成することが課題ではありますが、まずはここで次に進みます。
モデルの準備
# 学習モデル
from sklearn.linear_model import LinearRegression,Ridge
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
# pipeline setting
pipelines = {
'ols': Pipeline([('scl',StandardScaler()),
('est',LinearRegression())]),
'ridge':Pipeline([('scl',StandardScaler()),
('est',Ridge(random_state=0))]),
'tree': Pipeline([('scl',StandardScaler()),
('est',DecisionTreeRegressor(random_state=0))]),
'rf': Pipeline([('scl',StandardScaler()),
('est',RandomForestRegressor(random_state=0))]),
'gbr1': Pipeline([('scl',StandardScaler()),
('est',GradientBoostingRegressor(random_state=0))]),
'gbr2': Pipeline([('scl',StandardScaler()),
('est',GradientBoostingRegressor(n_estimators=250,
random_state=0))])
}
#pipelineを作成するために一旦作成 sample_pred = sample.iloc[:, 1]
# build and evaluate
scores = {}
for pipe_name, pipeline in pipelines.items():
pipeline.fit(X_train, y)
scores[(pipe_name,'train')] = r2_score(y, pipeline.predict(X_train))
scores[(pipe_name,'test')] = r2_score(sample_pred, pipeline.predict(X_test))
print(pd.Series(scores).unstack())
これを実行すると非常にびっくりする評価になります。マイナス評価が突然出てきます。うん、失敗・・・
予測
model = GradientBoostingRegressor(
min_samples_split = 5,
min_samples_leaf = 52,
max_depth = 6,
max_features = 'sqrt',
subsample = 0.8)
model.fit(X_train, y)
まずGradientBoostingRegressorでモデルを作成し、予測してみます。
# 予測 pred = model.predict(X_test) print(pred)
predに予測した値が入っているので、提出用ファイルsample[1]に代入し、CSV出力します。
sample[1] = pred
sample.to_csv('GradientBoostingRegressor.csv', index=None, header=None)
精度は高くなかったです。
予測:グリッドサーチ(1)
次はグリッドサーチを使ってみます。
scikit learnにはグリッドサーチなる機能がある。機械学習モデルのハイパーパラメータを自動的に最適化してくれるというありがたい機能。
param = {'n_estimators': list(range(20, 101, 10)),
'learning_rate': list(np.arange(0.05, 0.20, 0.01))}
# scoringを neg_mean_squared_error(負のMSE)とする
gsearch1 = GridSearchCV(estimator = model,
param_grid = param,
cv = 5,
n_jobs=4,
scoring = 'neg_mean_squared_error')
#fitさせる
gsearch1.fit(X_train, y)
estimator = modelでは、前述のモデルmodelを参照しています。param_grid = paramは、パラメータセッティングの代入値です。
 グリッドサーチを行った結果、数値の最高打点の組み合わせは以下の通りです。
グリッドサーチを行った結果、数値の最高打点の組み合わせは以下の通りです。
# test精度の平均が最も高かった組み合わせを出力 print(gsearch1.best_params_)
予測し直し、再度CSVを出力します。
# 予測
pred_gsearch = gsearch1.predict(X_test)
sample[1] = pred_gsearch
sample.to_csv('GBR_pred_gsearch.csv', index=None, header=None)
予測:グリッドサーチ(2)
実は、いろいろ試した結果、RandomForestRegressorが一番よかったです。
params = {'n_estimators' : [10, 100, 500, 2000], 'n_jobs': [-1]}
# モデルにインスタンス生成
mod = RandomForestRegressor()
# ハイパーパラメータ探索
cv = GridSearchCV(mod, params, cv = 10, scoring= 'neg_mean_squared_error', n_jobs =1)
cv.fit(X_train, y)
# 予測
pred_cv = cv.predict(X_test)
sample[1] = pred_cv
sample.to_csv('RFR_gridserch.csv', index=None, header=None)
なんか最後グダグダになってしまい申し訳ございません。
最終スコア(暫定評価)は2.85800でした。
投稿者のスコアを見る限りまだまだ改良の余地があるようです精進します。
なりたい自分になれる
スキルアップならUdemy
私も利用し、高収入エンジニアになったのよ。未経験から機械学習、データサイエンティスト、アプリ開発エンジニアを目指せるコンテンツが多数あります。優秀な講師が多数!割引を利用すれば1,200円〜から動画購入可能です。!





